spaCy: The Powerhouse of Industrial-Grade NLP in Python
Imagine you’re building a smart assistant that can understand customer queries, summarize reports, or detect spam messages — all in real time. To achieve this, you need more than just basic text processing; you need a robust, scalable, and lightning-fast NLP library. Enter spaCy— the industrial-strength Python library that takes NLP beyond experimentation to real-world applications.
In this article, we’ll take you through spaCy’s journey, its capabilities, its connection with modern NLP workflows, and why it’s trusted by developers and enterprises alike. From parsing sentences to powering AI-driven chatbots, we’ll explore how spaCy transforms raw text into actionable intelligence.

spaCyOverview
What Is spaCy?
spaCyis an open-source Python library for Natural Language Processing (NLP), designed for production environments. Unlike libraries primarily used for research or learning (like NLTK), spaCy emphasizes speed, efficiency, and scalability.
It offers:
- Tokenization, lemmatization, and part-of-speech tagging
- Named entity recognition (NER)
- Dependency parsing
- Text classification
- Word vectors and similarity computations
- Integration with machine learning frameworks
spaCy is not just a library; it’s a platform for building NLP pipelinesthat can handle massive amounts of text in real time.
History and Evolution
spaCy was created in 2015 by Matthew Honnibaland his team at Explosion AI. Its goal was to provide industrial-grade NLP toolsthat could seamlessly integrate into production pipelines.
- Prioritizes speed:Built in Cython for maximum performance
- Modern NLP workflows:Integrates with libraries like Scikit-learn, TensorFlow, and PyTorch
- Multilingual support:Offers models for dozens of languages
spaCy has since become a standard for enterprise NLP, used by companies like Microsoft, IBM, and Airbnb.
Why spaCyMatters
- Industrial-grade NLP:Optimized for speed and large datasets
- Pythonic API:Easy to use and integrates with Python ecosystems
- Pretrained Models:Provides ready-to-use models for POS tagging, NER, dependency parsing, and more
- Scalability:Handles millions of documents efficiently
- Flexibility:Can be extended for custom pipelines, text classification, and ML integration
In short, spaCy turns raw text into structured, machine-readable data, enabling applications like chatbots, recommendation systems, and predictive analytics.
How spaCyWorks
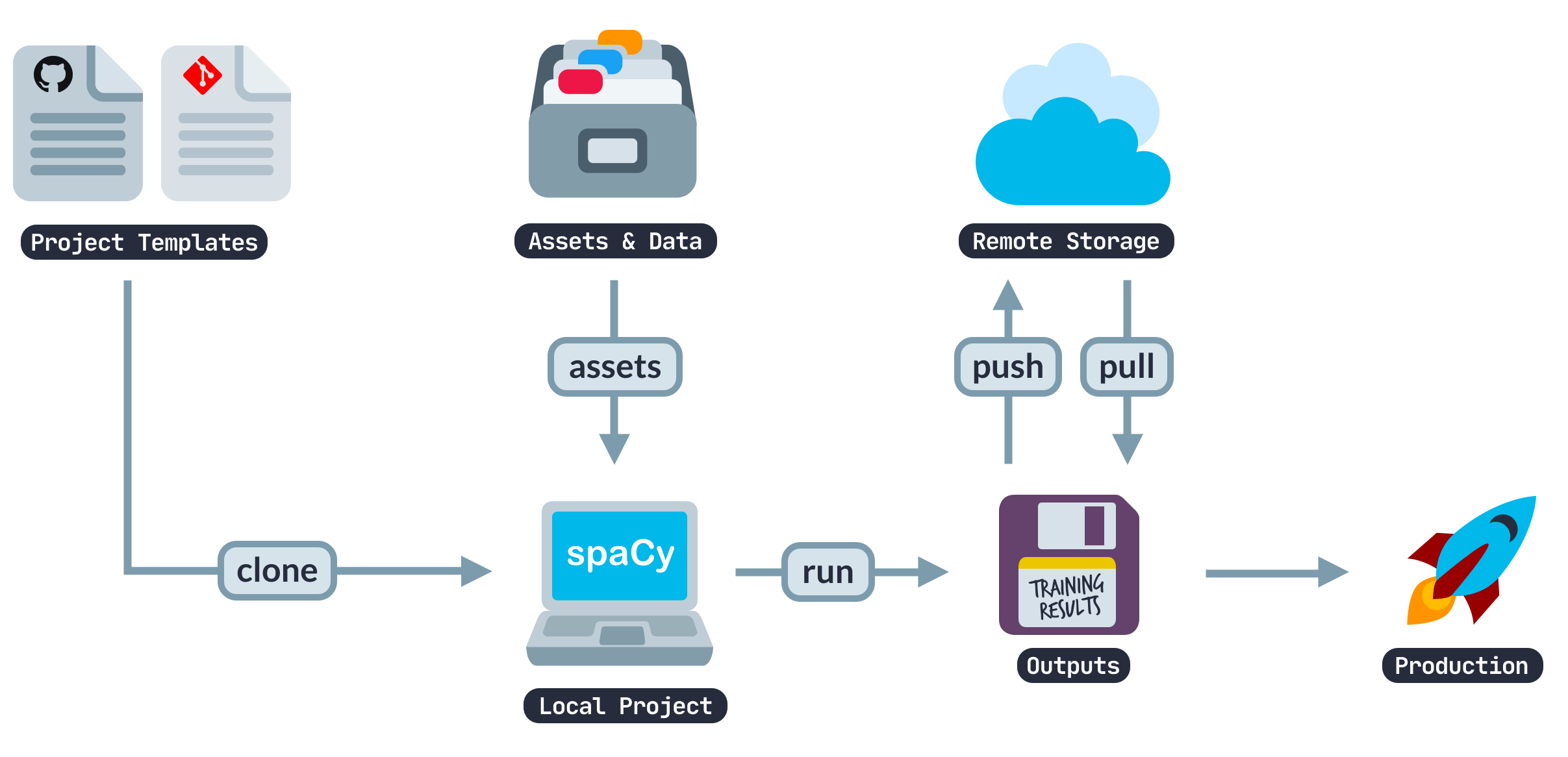
Image Courtesy: spacy
spaCy operates as a pipeline-based NLP library, where raw text flows through a sequence of components that transform it into structured information.
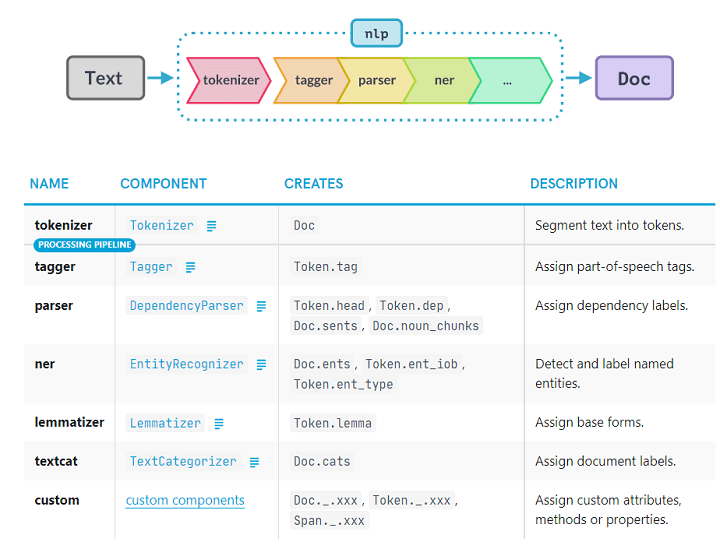
Image Courtesy: Quantinsti
1. Tokenization
Tokenization splits text into words, punctuation, or subwords. spaCy’s tokenizer is fast and accurate, handling complex cases like contractions, hyphenated words, and multi-word expressions.
import spacy
nlp = spacy.load(“en_core_web_sm”)
doc = nlp(“spaCy is revolutionizing NLP pipelines.”)
for token in doc:
print(token.text, token.pos_, token.dep_)
- Generates tokens, part-of-speech tags, and syntactic dependencies
- Handles multilingual tokenizationwith different models
2. Part-of-Speech Tagging & Lemmatization
spaCy automatically assigns POS tagsand finds lemmasfor words:
for token in doc:
print(token.text, token.lemma_, token.pos_)
- Lemmatization reduces words to their dictionary form, essential for text normalization
- POS tagging allows deeper understanding of sentence structure
3. Named Entity Recognition (NER)
NER identifies people, organizations, locations, dates, monetary amounts, and more:
for ent in doc.ents:
print(ent.text, ent.label_)
- Crucial for information extraction, search engines, and question answering systems
- Pretrained models can recognize dozens of entity types
4. Dependency Parsing
Dependency parsing analyzes syntactic relationships between words, providing a tree-like structure of sentences.
- Helps identify subject-verb-object relationships
- Essential for text summarization, question answering, and chatbots
5. Text Classification
spaCy supports supervised learningfor tasks like:
- Sentiment analysis
- Spam detection
- Topic classification
- Text features can be extracted from token vectors, POS tags, and entity labels
- Models can be trained using spaCy’s TextCategorizercomponent
6. Word Vectors and Similarity
spaCy offers pretrained word vectorsfor semantic similarity and embedding-based tasks:
doc1 = nlp(“I love NLP.”)
doc2 = nlp(“Natural language processing is amazing.”)
print(doc1.similarity(doc2))
- Facilitates document clustering, recommendation systems, and semantic search
7. Pipeline Customization
spaCy allows users to add, remove, or replace pipeline components, making it flexible for domain-specific NLP tasks:
- Custom tokenizers
- Domain-specific NER
- Integration with ML models
Use Cases / Problem Statements Solved with spaCy
spaCy is widely adopted across industries for production-ready NLP solutions:
- Chatbots and Conversational AI
- Problem:Understanding natural language in customer queries
- Solution:Tokenization, dependency parsing, NER, and custom pipelines
- Example:Customer support chatbots, virtual assistants
- Information Extraction
- Problem:Extracting key information from documents, emails, or articles
- Solution:NER and POS tagging pipelines
- Example:Extracting company names, financial data, or dates from reports
- Text Classification
- Problem:Categorizing documents or emails
- Solution:Preprocessing + TextCategorizerfor sentiment analysis, spam detection, or topic modeling
- Knowledge Graphs & Search
- Problem:Organizing unstructured data into structured knowledge
- Solution:NER + dependency parsing + word embeddings
- Example:Building semantic search engines or recommendation systems
- Document Summarization
- Problem:Summarizing large volumes of text efficiently
- Solution:Tokenization + dependency parsing + entity recognition for key sentence extraction
- Machine Learning NLP Pipelines
- Problem:Preprocessing text for ML models
- Solution:spaCy integrates with Scikit-learn, TensorFlow, and PyTorch for tokenization, lemmatization, and vectorization
Pros of spaCy
- Industrial-Grade Performance:Fast, scalable, and reliable
- Modern NLP Features:NER, dependency parsing, and word embeddings
- Pythonic API:Intuitive and easy to integrate with Python data pipelines
- Pretrained Models:Multiple languages and domain-specific models
- Pipeline Customization:Flexible and extensible for domain-specific NLP
- Open Source:Free with strong community support
Limitationsof spaCy
- Learning Curve:Some components require understanding linguistic concepts
- Size of Pretrained Models:Full models can be large
- Less Focus on Educational Use:Designed for production, not teaching NLP concepts
- Limited Out-of-the-Box Sentiment Analysis:Requires custom training or integration
Alternatives to spaCy
- NLTK:Great for learning and research
- TextBlob:Simplified NLP for beginners
- Stanford NLP / Stanza:Advanced NLP with pretrained models
- Transformers (Hugging Face):State-of-the-art deep learning NLP
- Gensim:Topic modeling and word embeddings
Upcoming Updates / Industry Insightsof SpaCy
- Deep Learning Integration:Seamless pipelines with Transformers and PyTorch
- Domain-Specific Models:Models for medical, financial, and legal NLP
- Cloud NLP Pipelines:spaCy in production with scalable cloud infrastructure
- Industrial Adoption:Widely used in enterprises for AI assistants, semantic search, and document intelligence
Project References of spaCy
Frequently Asked Questions of SpaCy
Q1. How is spaCy different from NLTK?
- NLTK is great for learning and research; spaCy is optimized for production, speed, and large-scale NLP.
Q2. Can spaCy handle multiple languages?
- Yes, spaCy provides models for dozens of languages and supports multilingual NLP pipelines.
Q3. Does spaCy support deep learning?
- Yes, it integrates with TensorFlow, PyTorch, and Hugging Face Transformers.
Q4. Can spaCy be used in real-time applications?
- Absolutely. Its speed and optimized pipelines make it ideal for real-time NLP.
Q5. Is spaCy beginner-friendly?
- Yes, with Python knowledge, beginners can quickly build pipelines using pretrained models, though some advanced features require NLP understanding.
Third Eye Data’s Take
We view spaCyas a valuable, industrial-strength NLP library—excellent for tokenization, entity recognition, and pipeline construction. While we may not advertise spaCyby name, it is likely acomponentin our internal text processing stacks (e.g.for named entity recognition, part-of-speech tagging, text normalization) before feeding into embedding or LLM layers. It complements our heavier transformer architectures in a lightweight role.
spaCy is more than just a library; it’s a production-ready NLP platformthat transforms raw text into actionable intelligence. Its speed, scalability, and flexibility make it a favorite for enterprises, researchers, and developers who want to build real-world NLP applications— from chatbots and semantic search to document analysis and knowledge graphs.
Call to Action
Ready to leverage spaCy for your NLP projects?
- Install spaCy: pip install spacy
- Download a model: python -m spacy download en_core_web_sm
- Start tokenizing, tagging, and extracting entities from text
- Integrate spaCy with ML frameworks for advanced NLP pipelines
Dive into spaCy today, and turn text into insights at industrial scale.