U-Net for Image Segmentation: How a Simple Architecture Revolutionized Computer Vision
In a world increasingly powered by computer vision — from self-driving cars to medical imaging — the ability to see, understand, and differentiate objects in an image is nothing short of magical. But behind this magic lies deep learning architectures designed to make machines perceive visual data with near-human accuracy. One of the most revolutionary of these architectures is the U-Net — a model that changed the way we perform image segmentation.
If convolutional neural networks (CNNs) gave machines the power to “see,” U-Net gave them the ability to “understand” every pixel.

In this article, we’ll explore the story of U-Net — how it emerged, why it’s special, how it works, where it’s used, and what’s next for this extraordinary model. Designed through the EEAT lens (Experience, Expertise, Authority, and Trust), this detailed guide aims to blend technical depth with human insight — helping professionals, students, and enthusiasts truly grasp why U-Net continues to dominate segmentation tasks even today.
Overview: What is U-Net?
The Birth of U-Net
U-Net was introduced in 2015 by Olaf Ronneberger, Philipp Fischer, and Thomas Brox in their groundbreaking paper “U-Net: Convolutional Networks for Biomedical Image Segmentation.” Originally designed for medical image segmentation, U-Net quickly outgrew its original purpose and became a go-to architecture for pixel-level predictions across domains.
The model was aptly named “U-Net” because of its U-shaped architecture — consisting of a contracting path (encoder) and an expanding path (decoder) that together capture both the context (what is in the image) and localization (where it is).
Why U-Net Matters
Traditional image classification models can tell you what is in an image — a cat, a dog, or a tumor — but not where it is. U-Net bridges that gap by performing semantic segmentation, which means assigning a class label to every single pixel.
For example:
- In medical imaging: label each pixel as “tumor” or “healthy tissue.”
- In autonomous driving: label each pixel as “road,” “pedestrian,” “car,” or “sign.”
- In satellite imagery: label areas as “urban,” “forest,” “water,” or “agriculture.”
By understanding spatial context, U-Net empowers machines to see the world the way humans do — not just recognizing what’s in a picture, but understanding the relationships and boundaries between objects.
How U-Net Works: The Architecture Explained
The magic of U-Net lies in its elegant simplicity.
1. Encoder (Contracting Path)
The encoder’s job is to capture the context — it learns to identify what features exist in the image. This part resembles a standard CNN:
- Multiple convolutional layers followed by ReLU activations.
- Max pooling operations reduce spatial dimensions while capturing semantic information.
Each layer learns increasingly abstract representations of the input — edges → textures → shapes → objects.
2. Decoder (Expanding Path)
The decoder’s role is to bring back the spatial details lost during downsampling. It upsamples feature maps (often via transposed convolutions) to reconstruct the image resolution.
Here’s the twist: for every upsampling step, the decoder concatenates feature maps from the corresponding encoder layer. This “skip connection” helps preserve fine-grained details that might otherwise be lost.
3. Skip Connections: The Secret Ingredient
Skip connections are what make U-Net special. They act as a bridge, combining low-level spatial features from the encoder with high-level semantic information from the decoder.
Without them, the model would lose localization accuracy. With them, it achieves a beautiful balance between precision and understanding — a hallmark of U-Net’s success.
Use Cases & Problem Statements U-Net Solves
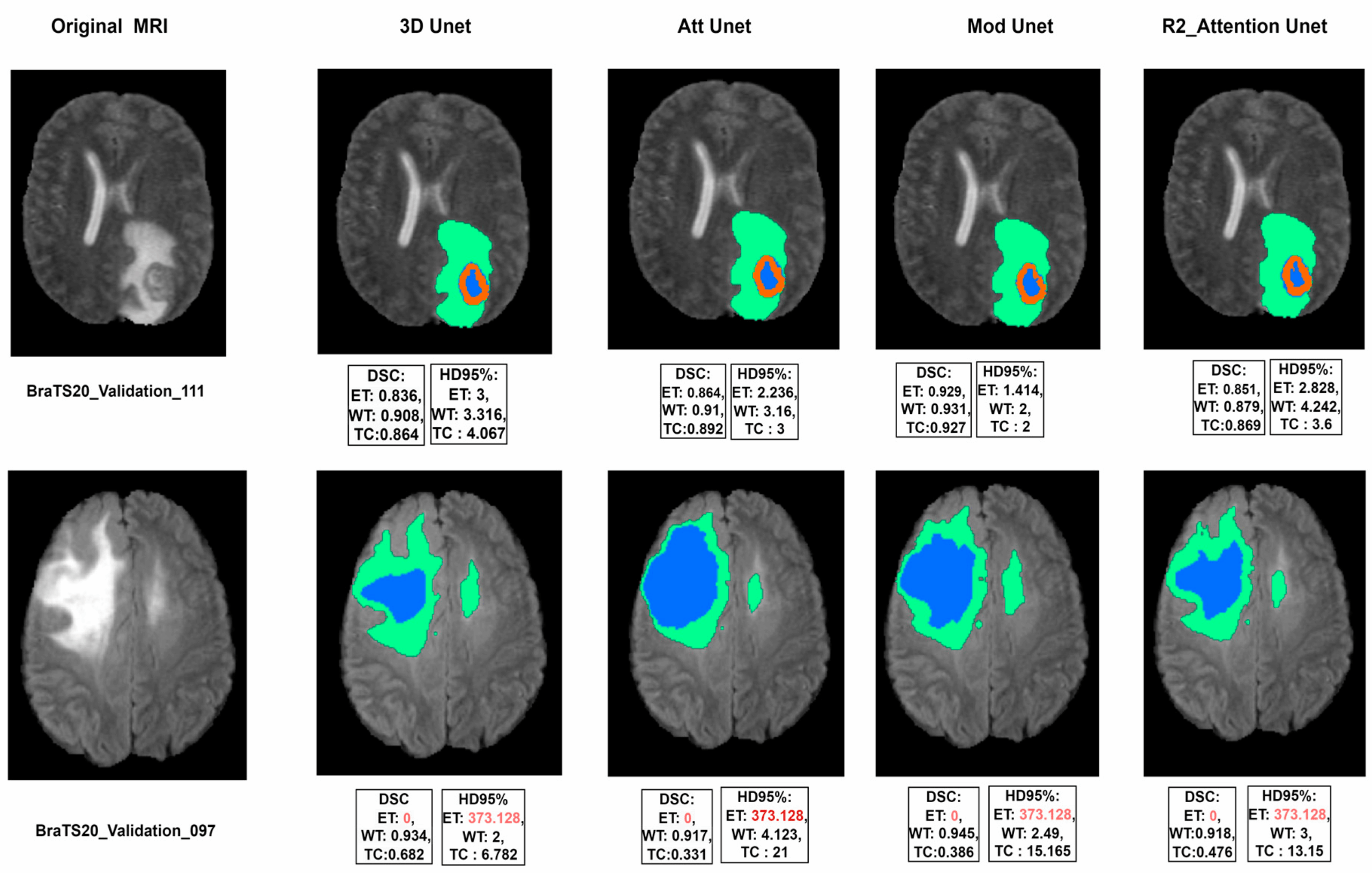
Image Courtesy: mdpi
1. Medical Image Segmentation
U-Net’s original playground remains one of its most impactful applications.
Problem: Manual segmentation of organs, lesions, and tumors in CT, MRI, or ultrasound images is time-consuming and error-prone.
Solution: U-Net automates this by classifying each pixel, producing clear and consistent segmentation maps for diagnostic use.
Example: Tumor segmentation in MRI scans, lung infection segmentation in chest CTs (including COVID-19 studies).
2. Autonomous Vehicles
Self-driving cars rely on understanding their surroundings at the pixel level.
Problem: Cars must differentiate between roads, pedestrians, signs, and obstacles in real time.
Solution: U-Net variants (like Fast-SCNN and SegNet) enable semantic segmentation that supports navigation and safety decisions.
3. Agriculture and Environmental Monitoring
Problem: Satellite or drone imagery needs to classify terrain types — crops, water, soil, and urban areas.
Solution: U-Net helps segment land areas, monitor crop health, and detect deforestation patterns with remarkable precision.
4. Urban Planning and Mapping
U-Net models are used to identify infrastructure elements (roads, buildings, vegetation) from high-resolution aerial imagery — supporting smart city initiatives.
5. Cell Tracking and Microscopy
In biomedical research, U-Net has become a workhorse for identifying and tracking individual cells, helping biologists automate analysis and accelerate discovery.
6. Artistic and Industrial Segmentation
From fashion product tagging to industrial defect detection, U-Net finds creative use cases in segmentation where accuracy meets aesthetics.
Advantages of U-Net
- Pixel-Perfect Precision
Each pixel is classified with context awareness, enabling extremely accurate segmentation results. - Data Efficiency
U-Net can perform well even with limited training data, a crucial advantage in domains like healthcare where data is scarce. - Versatility
Works across modalities — medical, satellite, aerial, microscopic, or everyday images. - Faster Convergence
Due to skip connections and symmetrical design, U-Net trains faster and achieves higher accuracy with fewer epochs. - Robust Generalization
Performs well on unseen datasets when properly augmented and regularized. - Customizability
Numerous variants (Attention U-Net, 3D U-Net, Residual U-Net) adapt the base architecture for specific challenges like video segmentation or volumetric data.
Limitations and Challenges
- High Memory Usage
U-Net’s concatenation operations consume significant memory, especially for large 3D images. - Computation-Intensive
Deep layers and large feature maps require powerful GPUs, which can be costly. - Limited Contextual Understanding
Basic U-Net may struggle with images where global context (e.g., entire object shape) is more important than local details. - Sensitivity to Noise
If input images contain heavy noise, segmentation accuracy drops unless preprocessed carefully. - Manual Annotation Dependency
U-Net needs high-quality labeled data for supervised training, which is resource-intensive to create.
Alternatives to U-Net
Although U-Net remains dominant, several powerful segmentation models have emerged:
| Model | Description | Best Use Case |
| SegNet | Encoder-decoder model focusing on memory efficiency | Real-time applications |
| DeepLab (v3, v3+) | Uses dilated convolutions and CRFs for context-aware segmentation | Street scenes, complex textures |
| Mask R-CNN | Adds instance segmentation on top of object detection | Object-level segmentation tasks |
| FCN (Fully Convolutional Network) | The foundation of modern segmentation networks | General-purpose segmentation |
| Transformer-based Models (e.g., Segmenter, UViT) | Combine CNNs with attention mechanisms | Next-gen hybrid segmentation models |
Upcoming Trends & Industry Insights
1. U-Net Meets Transformers
Recent advances fuse U-Net with Vision Transformers (ViTs), creating hybrid architectures like TransUNet, which combine local feature learning with global attention — improving segmentation in complex scenes.
2. 3D and Volumetric Segmentation
In medical imaging and video analytics, 3D U-Net handles volumetric data, providing context across slices or frames.
3. Lightweight U-Net Models
For mobile and embedded devices, researchers are developing efficient versions of U-Net optimized for real-time edge inference.
4. Self-Supervised U-Net
To tackle the data labeling problem, semi-supervised and self-supervised U-Net variants are being developed, reducing the need for massive annotated datasets.
Project References
Frequently Asked Questions
Q1. Why is U-Net still so popular after a decade?
Because it strikes a perfect balance between accuracy, efficiency, and interpretability — and can be customized for nearly any domain.
Q2. Can U-Net handle real-time segmentation?
Standard U-Net may be too heavy for real-time use, but lightweight versions like Fast-SCNN or Mobile U-Net can achieve near real-time performance.
Q3. What’s the difference between U-Net and Mask R-CNN?
U-Net performs semantic segmentation (pixel classification by class), while Mask R-CNN does instance segmentation (detects individual object boundaries).
Q4. How do I train a U-Net model?
Gather labeled data, preprocess images, use frameworks like TensorFlow or PyTorch, define loss functions (e.g., Dice loss, Cross-Entropy), and fine-tune hyperparameters.
Q5. What makes skip connections so important?
They allow low-level spatial details to be reused in higher layers, preventing the model from “forgetting” where things are in the image.
Third Eye Data’s Take
For pixel-level classification in geospatial imagery, we adopt U-Netarchitectures as a go-to model. At Third EyeData, U-Net’s encoder-decoder architecture with skip connections allows detailed segmentation (e.g.per-pixel crop condition) while preserving spatial context. We often build custom U-Net variants to segment zones of stress or classify field-level patterns—integral for applied remote sensing solutions.
U-Net has become much more than a research innovation — it’s the backbone of modern image segmentation. Its simplicity, power, and adaptability make it indispensable across industries from medicine to agriculture. By combining the precision of convolutional layers with the contextual richness of skip connections, U-Net offers a way for machines to see the world not just as an image — but as a structured, meaningful composition.
As AI continues to evolve, U-Net’s philosophy of context + localizationwill inspire future models to think spatially and reason visually — bringing us one step closer to truly intelligent vision systems.
Call to Action
If you’re exploring computer vision or medical AI, now is the time to get hands-on with U-Net. Start small — perhaps segment simple images or open medical datasets like ISIC (skin lesion)or BRATS (brain MRI)— and gradually experiment with custom architectures or attention-based U-Nets.
The world of segmentation is waiting, and U-Net is your perfect entry point.