Why Random Forest is a Game-Changer in Machine Learning
Imagine standing in a dense forest. Each tree is unique, but together they form a complex ecosystem. Now, imagine if each tree could make a decision about the forest’s health — and then the forest as a whole could make a better decision by combining all their insights.
That’s exactly how Random Forest, one of the most popular machine learning algorithms, works. It takes the wisdom of many decision trees and combines them to create a robust, accurate, and highly versatile model.
From predicting customer behavior to diagnosing diseases, Random Forest is a backbone in modern AI applications. In this article, we’ll explore what Random Forest is, how it works, its applications, pros and cons, alternatives, and future trends — all while keeping it readable, relatable, and SEO-friendly.

Random Forest Overview
What Is Random Forest?
Random Forest (RF) is an ensemble learning algorithm primarily used for classification and regression. The concept is simple yet powerful: instead of relying on a single decision tree, Random Forest builds multiple decision trees and aggregates their outputs to make a final prediction.
Think of it like asking a group of experts rather than one expert. Each tree might make a slightly different decision, but collectively, they usually arrive at a more accurate, stable, and generalized outcome.
Random Forest is widely used because it:
- Reduces overfitting common in single decision trees
- Handles large datasets and high-dimensional data
- Works well with missing values and categorical features
The History of Random Forest
Random Forest was introduced by Leo Breiman in 2001 as an extension of bagging (Bootstrap Aggregation). Its design was influenced by the need to overcome limitations of single decision trees, which are prone to overfitting and instability.
Over the years, Random Forest has become a go-to algorithm in industries like finance, healthcare, e-commerce, and more.
How Random Forest Works
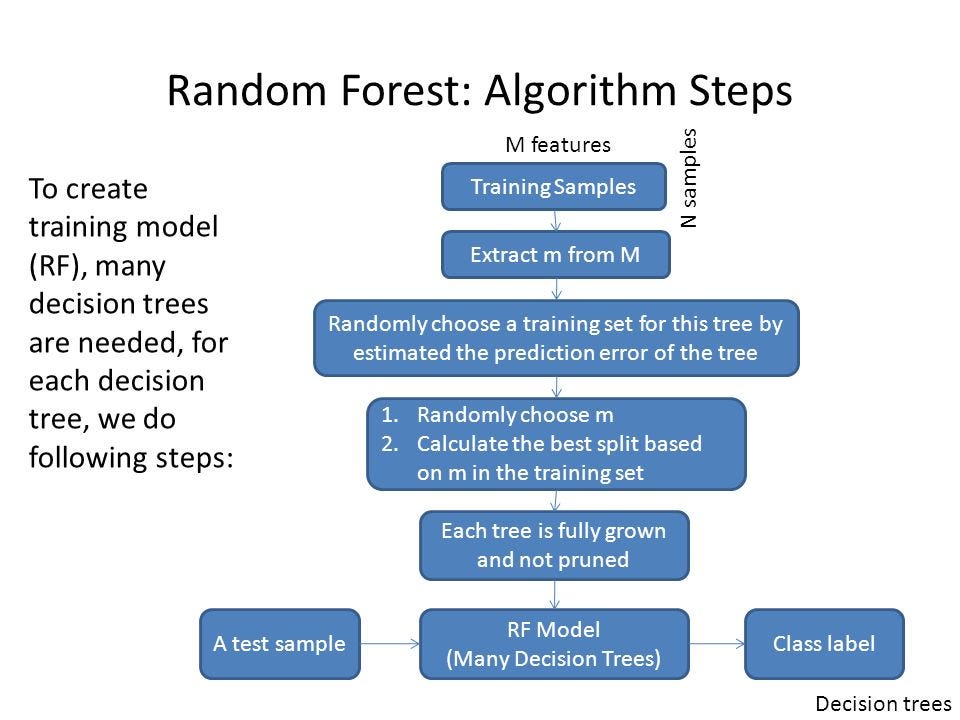
image Courtesy: medium
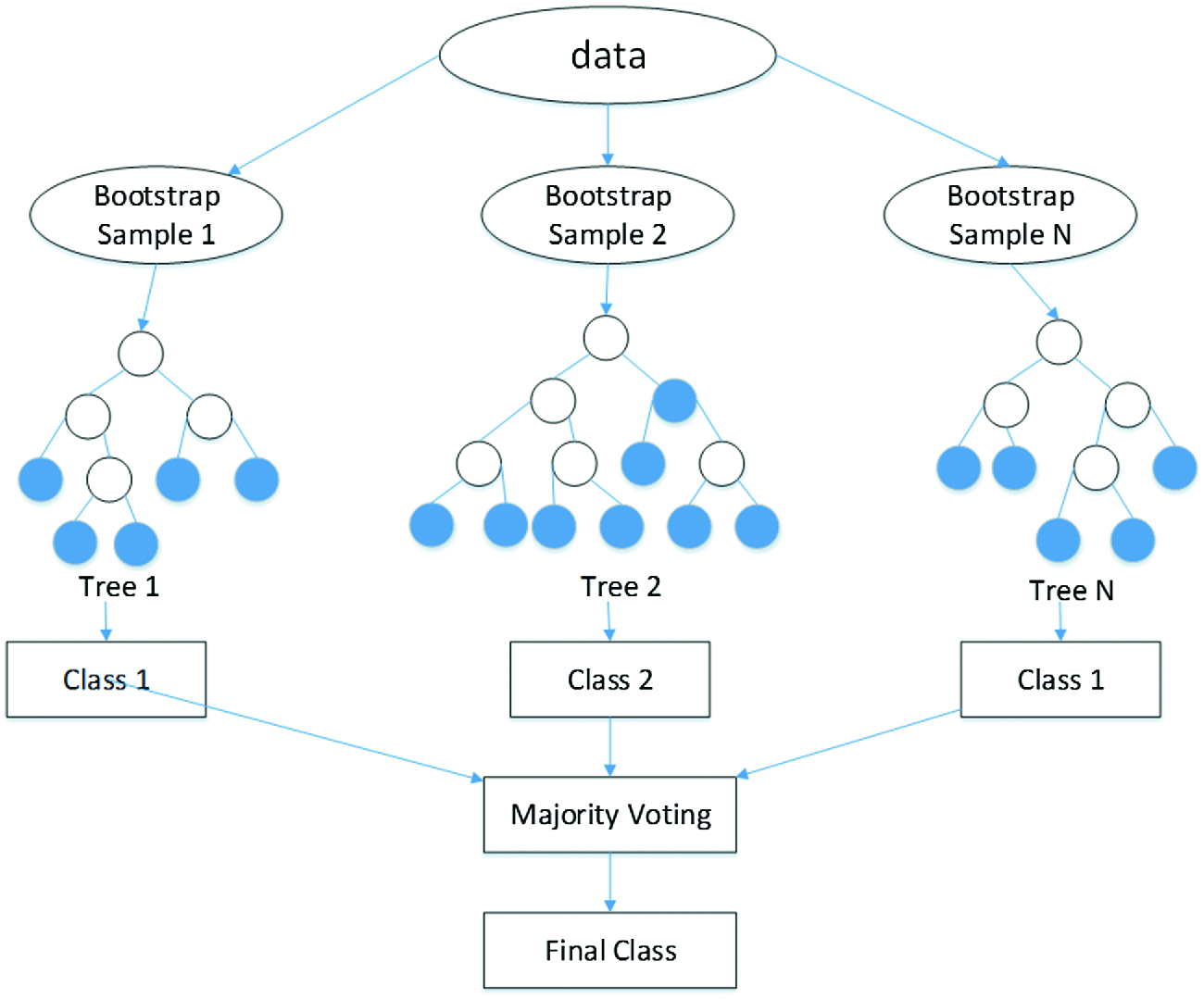
Image Courtesy: storage.googleapis
Random Forest is surprisingly intuitive once you break it down into steps:
1. Bootstrap Sampling
Random Forest uses a technique called bagging. It creates multiple subsets of the original dataset by random sampling with replacement. Each subset is used to train a separate decision tree.
This ensures diversity among trees, making the forest stronger collectively.
2. Decision Tree Construction
Each subset is used to build a decision tree, which splits data based on features that maximize information gain (or minimize impurity).
A key feature of Random Forest is feature randomness: at each split, it only considers a random subset of features rather than all features. This reduces correlation between trees and improves generalization.
3. Aggregating Predictions
- For Classification: Random Forest uses majority voting. Each tree votes on the class, and the most common class becomes the final prediction.
- For Regression: Random Forest averages the outputs from all trees to produce a continuous prediction.
This ensemble approach reduces variance, minimizes overfitting, and makes the model highly reliable.
4. Feature Importance
Random Forest can also tell you which features are most influential in prediction. By measuring how much each feature reduces impurity across all trees, you can rank features in order of importance — a powerful tool for feature selection and interpretability.
Use Cases / Problem Statements Solved with Random Forest
Random Forest is incredibly versatile, serving multiple domains and problem types. Let’s explore some key applications:
1. Customer Segmentation and Marketing
Businesses use Random Forest to predict customer behavior, segment audiences, and design targeted campaigns.
Example:
An e-commerce platform might predict which users are likely to churn or which products will appeal to which customer segment, optimizing marketing ROI.
2. Finance and Banking
Random Forest excels at fraud detection, credit scoring, and risk assessment due to its high accuracy and robustness.
Example:
Banks can analyze transaction patterns and detect anomalous behaviors that indicate potential fraud or credit default.
3. Healthcare and Diagnostics
Random Forest is widely used in medical diagnostics, disease prediction, and biomedical data analysis.
Example:
- Predicting whether a tumor is malignant or benign based on imaging and clinical features
- Analyzing gene expression datasets to identify disease markers
Its ability to handle high-dimensional data with correlated features makes it ideal for bioinformatics.
4. Stock Market Prediction
Financial analysts use Random Forest to forecast stock prices or market trends by analyzing historical data, economic indicators, and market sentiment.
5. Environmental and Geospatial Analysis
Random Forest helps classify land cover types, predict air quality, and model climate patterns using satellite imagery and environmental sensor data.
6. Manufacturing and Quality Control
Random Forest can predict equipment failure, detect defective products, and optimize supply chains in manufacturing environments.
7. IT and Cybersecurity
Random Forest is applied in intrusion detection, malware classification, and anomaly detection in network traffic.
Pros of Random Forest
Random Forest stands out for many reasons:
- High Accuracy:
Ensemble of trees reduces overfitting and improves generalization. - Handles High-Dimensional Data:
Works well when the number of features is very large. - Feature Importance:
Provides insight into which features matter most for predictions. - Robust to Outliers and Noise:
Less sensitive to anomalies compared to single decision trees. - Versatile:
Can handle classification, regression, and even multi-class problems. - Minimal Preprocessing:
Works well with missing values and does not require feature scaling.
Cons and Limitations
- Complexity and Resource Usage:
Training hundreds of trees requires computational power and memory. - Less Interpretability:
Compared to a single decision tree, Random Forest is harder to visualize and interpret. - Slower Predictions for Large Models:
Aggregating predictions from many trees can be time-consuming in real-time applications. - Overfitting in Noisy Data:
Though robust, Random Forest can overfit when trees are very deep and data is noisy. - Not Ideal for Sparse Data:
Algorithms like SVM or gradient boosting may perform better with sparse or text-based datasets.
Alternatives to Random Forest
Sometimes other algorithms are preferable depending on the problem:
- Gradient Boosting Machines (GBM):
More sequential learning, often higher accuracy but slower training. - XGBoost / LightGBM / CatBoost:
Optimized boosting frameworks, great for structured tabular data. - Decision Trees:
Simple and interpretable, but less accurate than Random Forest. - Support Vector Machines (SVM):
Effective for smaller, high-dimensional datasets. - Neural Networks:
Better for unstructured data like images, audio, and text.
Upcoming Updates / Industry Insights
1. Random Forest in AutoML
Modern AutoML frameworks automatically optimize Random Forest hyperparameters for faster deployment.
2. Integration with Big Data Platforms
Random Forest is now widely supported in Spark MLlib and H2O.ai, enabling large-scale distributed training.
3. Hybrid Models
Combining Random Forest with deep learning features for tabular-image fusion tasks is gaining traction in healthcare and finance.
4. Explainable AI (XAI)
With regulatory focus on model transparency, techniques like SHAP and LIME make Random Forest predictions more interpretable.
Project References
Frequently Asked Questions
Q1. How does Random Forest differ from a single decision tree?
Random Forest combines multiple trees for robust predictions, while a single tree is prone to overfitting.
Q2. How do I choose the number of trees?
Typically, 100-500 trees are used. More trees improve stability but increase computation.
Q3. Can Random Forest handle missing data?
Yes, it can handle missing values using surrogate splits or by ignoring missing data in tree construction.
Q4. Is Random Forest suitable for real-time predictions?
It can be, but very large forests may be slow. Pruning trees or limiting depth can help.
Q5. Why is Random Forest called “random”?
Because it uses random subsets of data and features to build each tree, reducing correlation among trees.
Third Eye Data’s Take
For predictive and classification tasks within our remote-sensing and agricultural AI solutions, we lean on Random Forestfor its interpretability, robustness to overfitting, and handling of non-linear relationships in tabular and spectral feature spaces. In our systems, Random Forest provides a reliable modeling baseline and often forms part of ensemble or hybrid pipelines.
Random Forest is like a forest of wisdomin the world of machine learning. By combining multiple decision trees, it achieves high accuracy, robustness, and versatility — making it an invaluable tool across industries.
Whether it’s predicting customer churn, detecting fraud, classifying diseases, or analyzing environmental data, Random Forest continues to deliver reliable, interpretable insights.
Call to Action
Ready to leverage the power of Random Forest?
- Start with Python’s Scikit-learnor H2O.ai
- Load your dataset, train a Random Forest model
- Experiment with hyperparameters like number of trees, depth, and feature subsets
- Visualize feature importance and improve your decision-making insights
The forest is waiting — it’s time to let your data speak and make smarter decisions!







