Vector Databases and Their Core Building Blocks: Milvus, Chroma, HNSW, PQ, and Hierarchical Partitioning
Imagine searching for an answer online and finding exactly what you meant — not just what you typed.
You ask your AI assistant, “Show me ways to make my code faster,” and it instantly brings up resources about algorithm optimization, vectorization, and caching techniques.
That’s not keyword matching — that’s semantic understanding.
And behind that understanding lies a new kind of engine: the vector database.

As artificial intelligence evolves, traditional databases can’t keep up with the way modern models understand meaning.
To bridge that gap, AI systems rely on embeddings — numerical representations of meaning — and vector databases that can store, search, and scale those embeddings efficiently.
In this article, we’ll explore the five key components that make vector databases powerful:
Milvus, Chroma, HNSW, PQ (Product Quantization), and Hierarchical Partitioning.
These aren’t just technologies; they’re the gears of the semantic search revolution — powering systems from chatbots to recommendation engines, from enterprise data platforms to the next generation of Retrieval-Augmented Generation (RAG).
The Architecture of Vector Intelligence
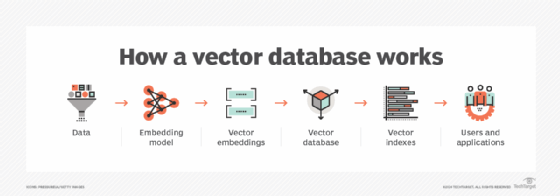
Image Courtesy: Techtarget
A vector databaseis a specialized system built to handle high-dimensional embeddings— the numerical fingerprints of words, sentences, images, or sounds that represent meaning.
Instead of matching exact words, vector databases find similarity in meaning. For example, “doctor” and “physician” might be stored close together in the vector space, even though the words are different.
They are critical for:
- Semantic search
- Recommendation systems
- AI chatbots
- Image and video retrieval
- RAG (Retrieval-Augmented Generation)pipelines
In short:
- Milvusand Chromaare the “engines” (databases).
- HNSW, PQ, and Hierarchical Partitioningare the “gears” (the internal mechanics). Together, they create a search system that thinks in meaning, not keywords.
Milvus — The Scalable Powerhouse
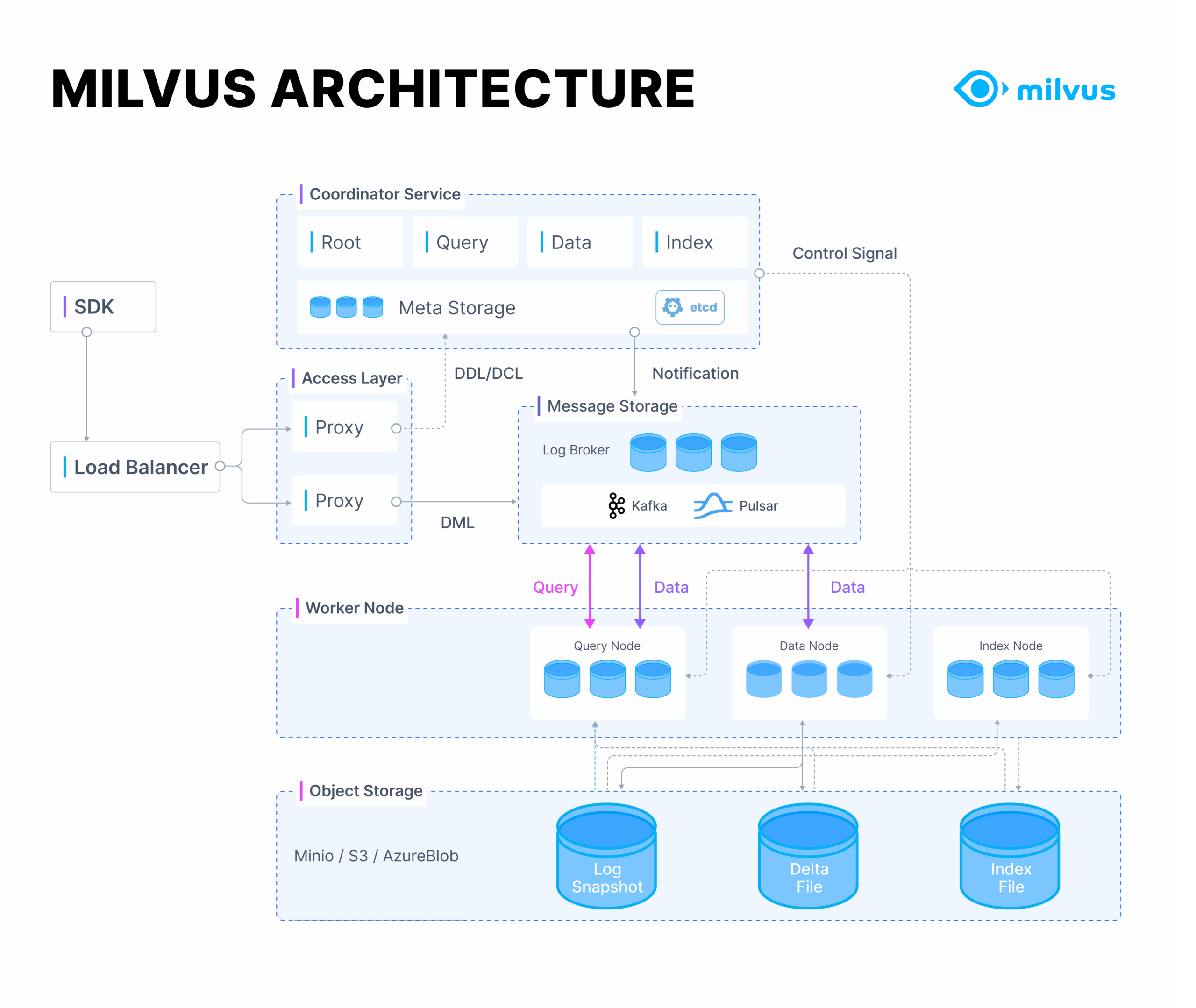
Milvus architecture
Milvus is an open-source vector databasedesigned for handling millions or even billions of embeddings. It’s built for enterprise-grade scalability, offering both distributed and GPU-accelerated search capabilities.
Developed by Zilliz, Milvus is the go-to platform for companies that need high-speed, high-volume semantic retrieval.
Use Cases / Problem Statements
- Searching across massive document repositories
- Powering AI-driven customer support systems
- Scaling RAG pipelinesto billions of embeddings
- Managing multimodal data(text, image, video)
Pros
Highly scalable for enterprise deployments
Supports multiple indexing algorithms (HNSW, IVF_PQ, FLAT)
Integrates easily with LangChain, LlamaIndex, Hugging Face
Handles hybrid searches (keyword + vector)
Cons
Setup and tuning require expertise
Index-building can be resource-intensive
Alternatives
- Weaviate(cloud-first, schema-based)
- Pinecone(fully managed vector database)
- Qdrant(Rust-based, performance-optimized)
Industry Insight
Milvus continues to lead in billion-scale vector storage, powering search in enterprises like Alibaba, Shopee, and Tencent. Its combination of speed, modularity, and distributed design makes it the backbone of modern AI retrieval systems.
Project Example
A global e-commerce company uses Milvus to serve visual product search— letting customers upload a photo and instantly find similar items.
Chroma — The Developer’s Playground
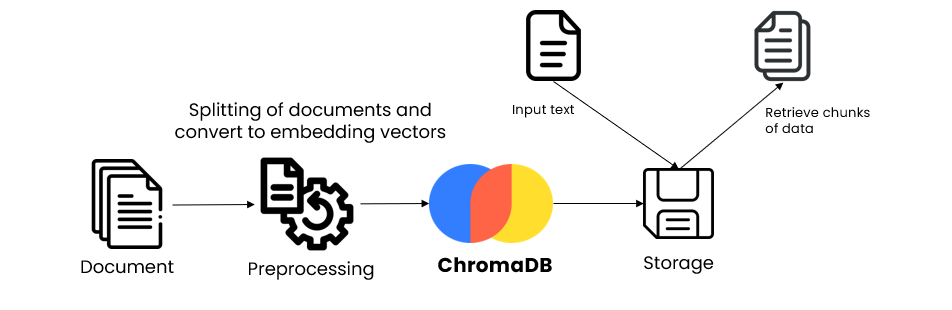
Image Courtesy: datadriveninvestor
Chroma (ChromaDB)is a lightweight, developer-friendly vector storeperfect for small to medium-sized AI applications — especially RAG systems. Think of it as the “SQLite of vector databases.”
Use Cases / Problem Statements
- Personal AI assistants
- Prototype RAG pipelines
- Knowledge-based chatbots
- Local LLM memory management
Pros
Simple, local setup (no server required)
Direct integration with LangChain & LlamaIndex
Easy to use — perfect for rapid prototyping
Ideal for research, testing, and development
Cons
Not suited for massive, distributed data
Limited in high-concurrency scenarios
Alternatives
- FAISS (Facebook AI Similarity Search)— for local vector testing
- Milvus Lite— for developers who want more scale
Industry Insight
Chroma dominates the LLM developer space, often used in RAG demos, prototypes, and small-scale apps. It bridges the gap between concept validation and production deployment.
Project Example
A startup uses Chroma to store all internal FAQs as embeddings. Their chatbot retrieves the best answers using LangChain, reducing customer support response time by 60%.
HNSW — The Speed Engine
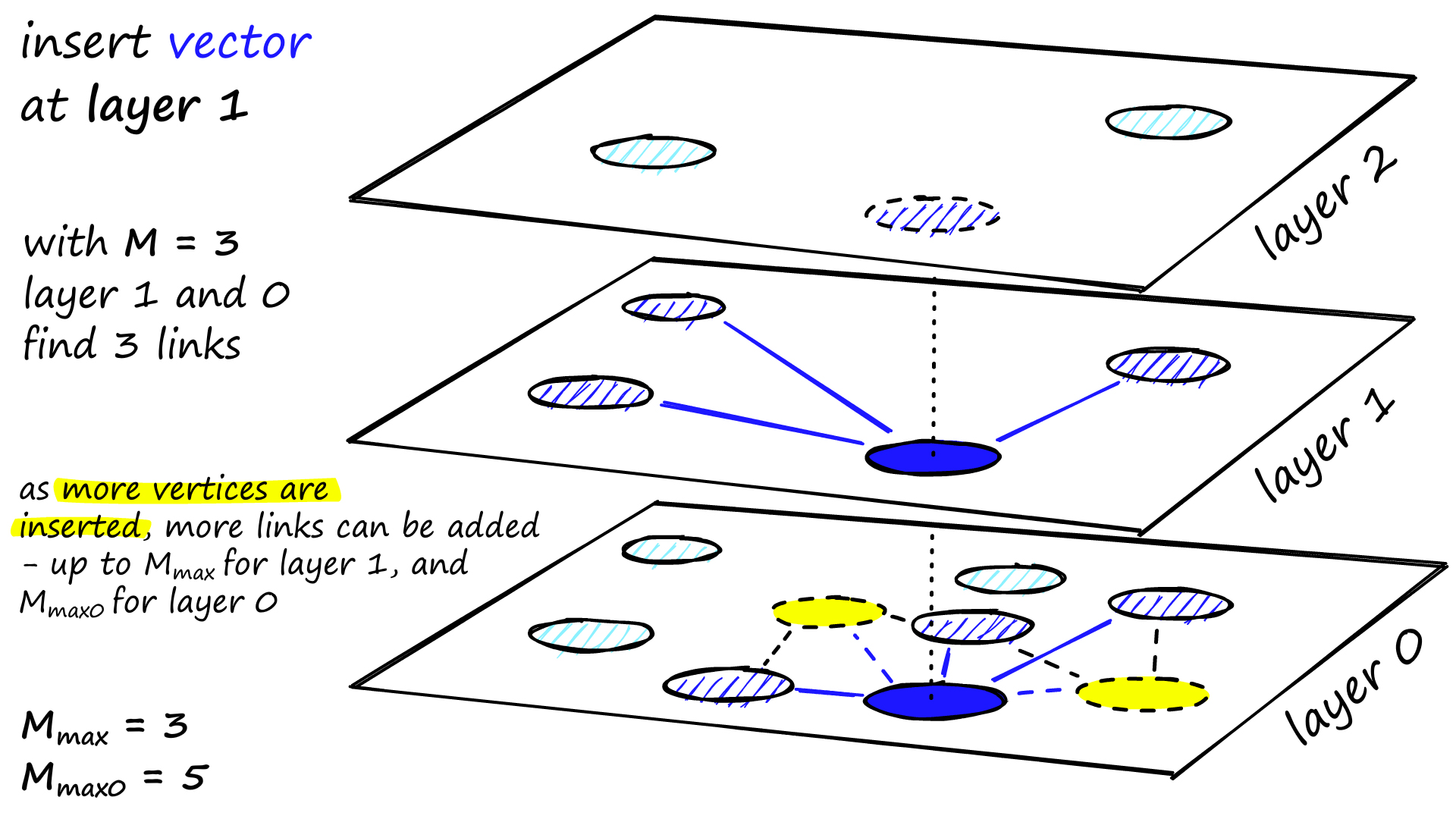
Image courtesy: Pinecone
HNSW (Hierarchical Navigable Small World)is a graph-based indexing algorithmthat powers ultra-fast approximate nearest neighbor (ANN)searches.
How It Works
HNSW builds a multi-layer graph:
- Upper layers connect distant nodes for long jumps (coarse search).
- Lower layers handle local refinements (fine search).
This lets queries “hop” through the graph efficiently, drastically reducing search time from O(N)to O(log N).
Use Cases / Problem Statements
- Real-time similarity search
- Recommendation systems
- RAG retrieval optimization
Pros
Extremely fast retrieval (sub-second)
Scales efficiently to millions of vectors
Maintains high accuracy with low recall loss
Cons
Requires fine-tuning parameters
High memory usage for large graphs
Alternatives
- IVF (Inverted File Index)— for simpler clustering-based search
- LSH (Locality-Sensitive Hashing)— faster but less accurate
Industry Insight
HNSW is the gold standardfor high-performance ANN search and is implemented in Milvus, FAISS, Weaviate, and Qdrant. It’s the secret sauce behind the speed of semantic search engines.
Project Example
An AI-driven media company uses HNSW for video similarity detection— scanning millions of video embeddings to prevent duplicate uploads.
PQ (Product Quantization) — The Compression Magician

Image Courtesy: Sudhiyelikar
Product Quantization (PQ)is a compression techniquethat reduces vector size while preserving search accuracy. It makes billion-scale searches possible on limited hardware.
How It Works
PQ splits each vector into smaller chunks (sub-vectors), assigns each a compact code, and stores only the codes instead of the full data.
During search, it computes approximate distances, achieving massive memory savings.
Use Cases / Problem Statements
- Large-scale image or text databases
- Memory-constrained environments
- Cost-efficient semantic search
Pros
4×–16× storage reduction
Enables large-scale search on affordable hardware
Works well with IVF and HNSW
Cons
Small accuracy trade-offs
Slower query time compared to uncompressed vectors
Alternatives
- Scalar Quantization (SQ)— simpler, less efficient compression
- Vector Compression via Autoencoders— for deep-learning-based optimization
Industry Insight
PQ is critical in enterprise AI search systems, especially in Milvus’s IVF_PQindex — balancing accuracy, performance, and cost.
Project Example
A media analytics firm compresses image embeddings using PQ in Milvus, reducing memory usage by 80% while maintaining 95% search accuracy.
Hierarchical Partitioning — The Organizer
Hierarchical Partitioningstructures data into multiple layers or clusters, enabling coarse-to-fine search. It’s like searching for a book first by genre, then by author.
How It Works
- Vectors are grouped into top-level clusters.
- Each cluster contains sub-clusters.
- A query first selects the relevant top-level cluster, then drills down for precision.
Use Cases / Problem Statements
- Large-scale document retrieval
- Domain-based data segmentation
- Latency-sensitive AI systems
Pros
Reduces search space drastically
Improves accuracy by focusing on relevant clusters
Works well with PQ and HNSW
Cons
Complex to tune
Cluster drift over time requires re-indexing
Alternatives
- Flat search(brute force) for smaller datasets
- Dynamic partitioningfor streaming data
Industry Insight
Hierarchical partitioning is the foundation of IVF_PQin Milvus and FAISS. It enables multi-level navigation in vector spaces, providing an optimal balance between speed and precision.
Project Example
An AI legal tech company uses hierarchical partitioning to segment millions of legal documents by topic before performing semantic retrieval.
How They Work Together?
| Stage | Component | Role |
| 1. Storage | Milvus / Chroma | Store and manage vector embeddings |
| 2. Indexing | HNSW | Build graph structures for fast retrieval |
| 3. Compression | PQ | Reduce memory footprint |
| 4. Partitioning | Hierarchical | Organize data for efficient lookup |
| 5. Query | Combined Stack | Deliver relevant, semantic results in milliseconds |
Together, these components form a high-speed, low-latency, meaning-aware search engine — powering everything from chatbotsto enterprise AI search portals.
Overall Stack Advantages
Scalability:Handle billions of embeddings seamlessly
Speed:Sub-second retrieval through HNSW
Efficiency:PQ ensures cost-effective operations
Precision:Hierarchical search improves accuracy
Flexibility:Works with both local and cloud ecosystems
Challenges to Consider
Alternatives
If you’re exploring beyond Milvus-Chroma stacks:
- Weaviate→ Schema-based, cloud-first, modular
- Pinecone→ Managed vector service (no infra overhead)
- Qdrant→ Lightweight, Rust-optimized
- FAISS→ Ideal for local or academic use
HNSW
HNSW is a graph-based index. Alternatives include other graph, clustering, and tree-based structures.
- Clustering-Based:
- IVFFlat (Inverted File with Flat Search): Divides vectors into lists (clusters) using $k$-means and searches only the nearest clusters.
- Tree-Based:
- Annoy (Approximate Nearest Neighbors Oh Yeah): Builds a forest of random projection trees for indexing.
- KD-Trees or Ball Trees: Recursively partitions the data space into smaller, nested regions.
- Graph/Disk-Optimized:
- DiskANN (and the underlying Vamana algorithm): Graph-based but specifically optimized for efficient search on disk (SSDs).
- Brute-Force:
- Flat Index: Compares the query vector against every vector in the dataset for perfect accuracy.
PQ
PQ (Product Quantization) is a vector compression technique. Alternatives offer different ways to reduce vector size.
- Scalar Quantization (SQ): Quantizes each vector dimension independently to a smaller data type (e.g., 8-bit integer).
- Optimized Product Quantization (OPQ): Applies an optimal rotation to the vectors before standard Product Quantization to improve compression effectiveness.
- Binary Quantization (BQ) / Locality-Sensitive Hashing (LSH): Maps high-dimensional vectors to compact binary codes for distance calculation using Hamming distance.
Hierarchical Partitioning
Alternatives for data organization and partitioning range from single-level clustering to system-level distribution strategies.
- Flat/Single-Level Clustering:
- $k$-means Clustering: Divides the vector space into a single level of distinct, non-overlapping clusters.
- Spatial Partitioning:
- Using structures like KD-Trees or Ball Trees to recursively partition the physical data space.
- Horizontal Scaling:
- Sharding: Distributing the entire vector index (e.g., HNSW or IVFFlat) across multiple physical machines to handle scale.
- Metadata-Based Partitioning:
- Partitioning or filtering vectors based on associated non-vector attributes (e.g., grouping by
categoryordate)
- Partitioning or filtering vectors based on associated non-vector attributes (e.g., grouping by
Industry Insights and Future Trends
- GPU-based Vector Search:NVIDIA’s cuVS is revolutionizing speed.
- Hybrid Search:Combining semantic and keyword filtering for better context.
- Dynamic Indexing:Real-time updates without full rebuilds.
- Multi-modal Vector Databases:Unified search across text, image, and audio.
Frequently Asked Questions
Q1:What’s the difference between Milvus and Chroma?
Milvus is built for scale; Chroma is built for simplicity.
Q2:Why use PQ in a vector database?
To reduce storage and improve speed on large datasets.
Q3:Is HNSW accurate?
Yes — it’s approximate, but recall rates often exceed 95%.
Q4:Can these be combined?
Absolutely — modern vector DBs use multiple techniques together (e.g., IVF_PQ + HNSW).
Project References
Third Eye Data’s Take
In the new age of AI, understanding meaningmatters more than matching words.
That’s what vector databasesdeliver — and behind their brilliance are the five pillars we explored:
Milvus, Chroma, HNSW, PQ, and Hierarchical Partitioning.
Together, they transform raw data into intelligent retrieval — making AI systems not just responsive, but truly context-aware.
Call-to-Action:
If you’re building AI systems — whether a chatbot, a recommendation engine, or a RAG pipeline — start exploring vector databases today.
Experiment with Chromafor small projects, scale with Milvus, and fine-tune with HNSWand PQ.
Because in the AI future, those who master vector intelligencewill master meaning itself.