Streaming the Future: How Google DatastreamKeeps Your Data in Sync
Imagine this: your engineering team runs a campaign dashboard that blends customer data from your transactional database, logs from application servers, and product catalogs stored in a cloud database. You wake up one morning to find the dashboard is showing stale, inconsistent numbers. A recent sale was recorded in your MySQL database, but the analytics pipeline hasn’t picked it up yet. Meanwhile, your customer support team is working off outdated product catalogs while replying to complaints. Your BI queries are returning partial or wrong results, and the analysts are frustrated dragging multiple CSV exports together.

In many organizations, data synchronizationis the weak link. Batch ETL jobs, nightly syncs, or manual pull operations are brittle, delayed, and error-prone. What if instead you could ensure that every change in your source databases(inserts, updates, deletes) is streamed reliably into your analytics or target systemsin near real time — without writing custom CDC code, managing streaming clusters, or worrying about schema drift?
That is exactly what Google Datastreampromises. It is a managed, serverless Change Data Capture (CDC) & replication serviceby Google Cloud that helps you continuously replicate and sync data across heterogeneous systems — e.g. from MySQL, Oracle, PostgreSQL, or SaaS sources into BigQuery, Cloud Storage, or Spanner — with minimal latency and minimal management burden.
What Exactly Is Datastream?
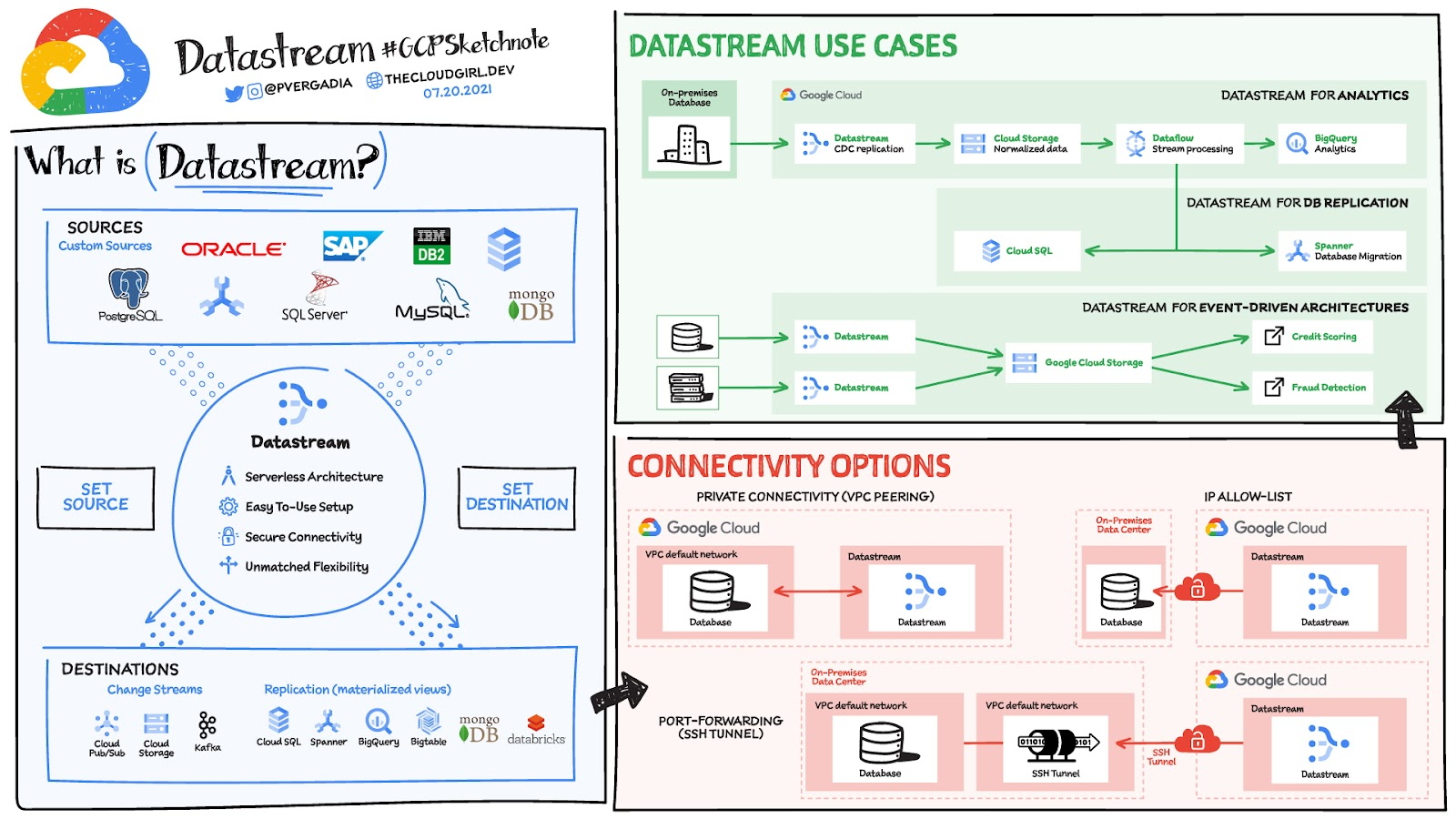
Image Courtesy: Google
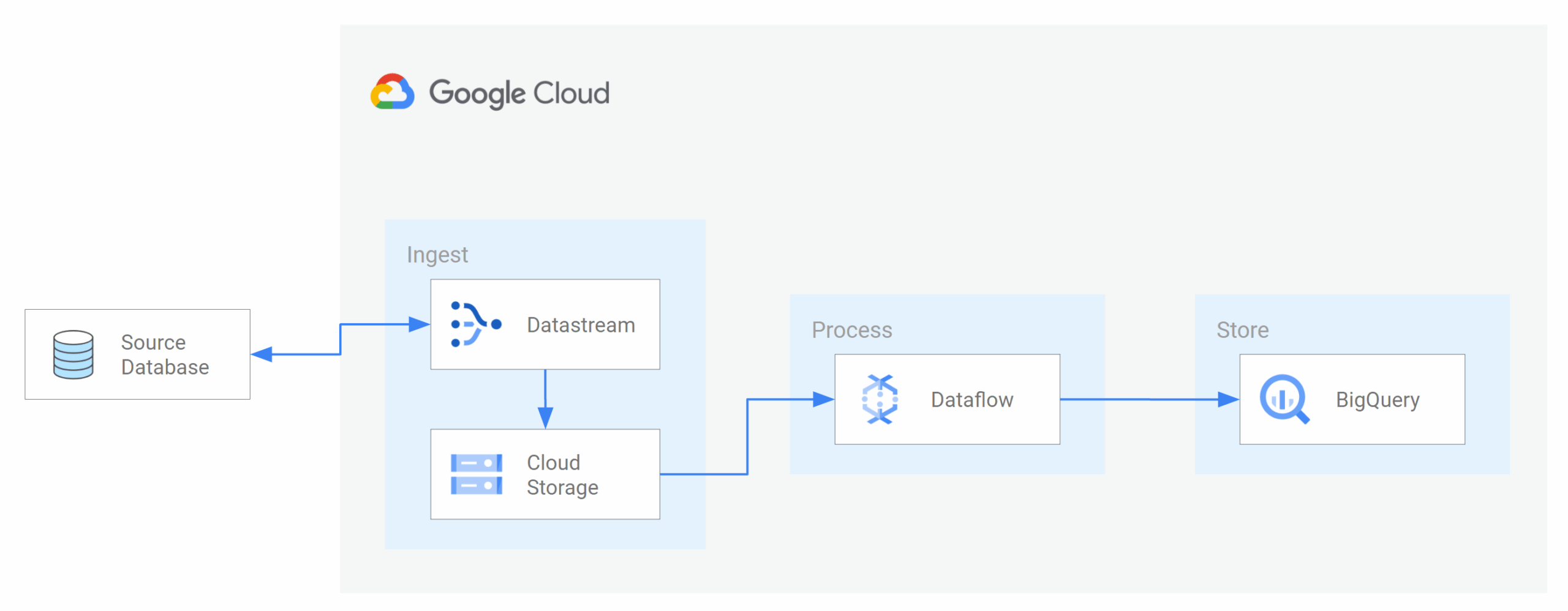
Image Courtesy: Google
At its core, Datastreamis a fully managed, serverless data replication and change-streaming service. It tracks changes (creates, updates, deletes) in your source databases via log-based CDC (Change Data Capture)and pipes them into target systems such as BigQuery, Cloud Storage, Cloud SQL, Spanner, or other destinations.
Key characteristics:
- Serverless & auto-scaling— no need to manage provisioning or cluster infrastructure. Datastream scales with workload.
- Low latency / “near real time”— changes are streamed and replicated with minimal delay. (Though real-world latency may vary; more on this later.)
- Heterogeneous source and destination support— supports multiple source databases (Oracle, MySQL, PostgreSQL, SQL Server, SaaS, etc.) and destinations including BigQuery, Cloud Storage, Spanner, Cloud SQL.
- Historical + CDC streaming— can backfill historical data (full snapshot) and then stream subsequent changes continuously.
- Automatic handling of schema changes— support for evolving schemas in your source systems without failing the replication pipeline.
- Secure connectivity options— VPC peering, private connectivity, IAM integration, and encryption in transit and at rest.
- Integration with Dataflow & Google’s data stack— you can use Dataflow templates to process or transform events delivered by Datastream.
Three core building elements in Datastream architecture are:
- Connection Profiles— define how Datastream connects to source systems and destinations (credentials, host, network settings).
- Streams— the logical definitions of data replication tasks (which tables, which change events, where to write).
- Private / network connectivity— ensuring secure, low-latency links between Datastream and your source/destination systems (often via VPC, peering, or VPN).
By combining these, Datastream becomes a powerful, low-op solution for keeping your data in sync across systems.
Use Cases / Problem Statements Solved with Datastream
Let’s explore when Datastream becomes the right tool, with practical examples and scenarios.
- Real-Time Analytics & Dashboards
Your organization wants dashboards that reflect near-current state rather than overnight syncs. For example:
- As soon as an order is placed in MySQL, that change is replicated to BigQuery so dashboards can show live sales numbers.
- Application metrics, logs, user actions, or clickstreams are reflected in analytics systems within minutes (or seconds).
Datastream + BigQuery (or Dataflow) often power such pipelines.
- Database Migrations & Replication
When migrating from on-premises or legacy databases (Oracle, MySQL, PostgreSQL) into Google Cloud, Datastream allows you to replicate data continuously, minimizing downtime:
- Backfill the entire database, then stream incremental changes.
- Maintain dual writes during cutover, then switch over once sync is assured.
- Keep the source and target in sync for rollback or fallback.
Schnuck Markets, for example, used Datastream to stream Oracle changes into BigQuery to keep data scientists up to date.
- Event-Driven Architectures / Microservices
Datastream can feed event streams into Cloud Storage or Pub/Sub-based systems, enabling microservices to react to data changes:
- When a row is inserted or updated in a database, emit an event to downstream services (e.g. inventory system, notifications, cache invalidation).
- Use Cloud Storage as a buffer or landing area, then trigger processing via Dataflow or Cloud Functions.
- Hybrid / Multi-Cloud Synchronization
You may have databases both on-prem and in Google Cloud — Datastream helps to bridge them by replicating changes across them in a secure, managed way.
- Data Lake Ingestion
Use Datastream to write change events (in Avro/JSON) into Cloud Storage. Then downstream pipelines can transform and load them into analytics systems.
- Feeding Machine Learning / Feature Updates
ML models often require feature tables updated regularly. Datastream can feed change streams so feature stores are kept near-real-time.
- Compliance / Auditing / Backup Streams
Because Datastream captures DML changes (INSERT, UPDATE, DELETE), it’s useful for auditing and building reversible event logs in your cloud environment.
Strengths & What Makes DatastreamValuable
Why many organizations adopt Datastream as their CDC backbone:
- Managed & Serverless
No clusters to manage, no infrastructure to provision. Datastream scales transparently.
- Minimal Impact on Source Systems
Because it uses log-based CDC (e.g. Oracle LogMiner, binlogs), it doesn’t require triggers or full table polling, and reduces load on your database.
- Support for Historical Backfill + Real-Time Streaming
You get a “snapshot + delta” model in one pipeline — no separate tools.
- Schema Evolution / Drift Handling
Datastream handles changes in source schemas (adding or removing columns) gracefully without breaking replication.
- Secure Connectivity
Private network support (VPC peering, VPN, private connectivity), IAM, encryption.
- Low-Latency / Near Real-Time Replication
While exact latencies depend on volume and architecture, Datastream delivers change events rapidly to targets.
- Integrated with Google Stack
Works seamlessly with Dataflow, BigQuery, Cloud Storage, Cloud SQL, Spanner, and others.
- Transparent Monitoring & Status Reporting
You can see status, latency, error rates, and health of replication pipelines via console.
- Multi-Source & Multi-Destination
Supports multiple source types (Oracle, MySQL, PostgreSQL) and destinations (BigQuery, GCS, Spanner).
- Evolving Feature Set
New features like streaming to new targets, better connectors, optimizations, and integrations keep it relevant.
Trade-Offs & Challenges of Google Datastream
No technology is perfect. Here are trade-offs, caveats, and challenges to consider when adopting Datastream:
- Latency Can Vary / Not Always “Instant”
Some users report delays (minutes) before changes propagate fully to BigQuery, especially under heavy load or misconfiguration.
- Cost Overhead
You pay for processed data (volume of change events, backfill) and possibly underlying Dataflow processing. Some Reddit users complain high cost for replicating large datasets continuously.
- At-Least-Once Delivery / Duplicates
Replication uses “at least once” semantics. Events may be duplicated, so downstream deduplication or safeguards are needed.
- Ordering / Out-of-Order Events
There is no guarantee of strict global ordering — metadata must be used to re-sort or reconcile.
- Configuration Complexity for Network / Access
Setting up connectivity (VPC peering, firewalls, network routing) across projects or VPCs can be tricky.
- Schema Limitations / Complex Types
Some complex source schemas or types may map poorly or require transformations.
- Backfill Load / Performance Impact
The initial snapshot (historical data) can cause high load and requires planning.
- Limited Destination Types / Maturity Gaps
Some targets or connectors might not yet be supported or may be in preview mode.
- Monitoring & Observability
While visibility is good, very large or complex pipelines may still be harder to monitor end-to-end when combined with transformation pipelines.
- Vendor Lock-In Considerations
Deep investment in Datastream + its integration may make future migration harder.
Alternatives approachesof Google Datastream
If Datastream doesn’t fully fit, here are other approaches (sometimes used alongside Datastream):
- Data Fusion / Cloud Data Fusion
A more feature-rich ETL/ELT tool with visual pipelines, transformations, connectors, and replication. It’s more “pipeline-heavy,” while Datastream is more focused on real-time replication.
- Custom CDC Solutions / Debezium / Kafka Connect
Use open-source CDC frameworks (Debezium) with Kafka or Pub/Sub to build your own replication pipeline. More control, but heavier ops.
- Batch ETL / Scheduled Jobs
For use cases where real-time isn’t required. Use regularly scheduled jobs to sync data from source to target.
- Database-native Replication
Some databases provide built-in replication or mirror mechanisms. If your architecture supports it, this may be sufficient (though often less flexible).
- Hybrid Approach
Use Datastream for delta (incremental changes) and batch pipelines for heavy lifts. Or use Datastream + Dataflow transformations to filter, join, or enrich before writing.
- Streaming Platforms / Messaging
Using platforms like Kafka, Pub/Sub, or Kinesis with transformation pipelines — Datastream can act as a source or feeder in such architectures.
Upcoming Updates & Industry Insights
Here are some evolving trends, new features, and directions around Datastream that signal where it’s going:
- Expansion of Source & Destination Support
Google is working to support more database systems, SaaS platforms, new destinations beyond BigQuery and Cloud Storage.
- Deeper Integration with Event-Driven Architectures
Enabling easier bridging to Pub/Sub or direct event buses so applications can react in real time to data changes.
- Better Schema Evolution / Change Handling
Continued improvements in handling complex schema drift, nested types, type changes, migrations.
- Performance Optimizations / Lower Latency
Google is pushing to reduce lag, improve throughput, and optimize replication under high load.
- Cost Optimization Tools / Smart Filtering
Tools that allow selective capture (filtering out less relevant columns or rows) to reduce cost and data movement.
- More Built-in Transformations / Enrichments
Similar to traditional ETL systems, Datastream may gain lightweight processing capabilities to filter/transform events before writing.
- Better Observability / AI-Driven Diagnostics
Automated alerts, suggestions, anomaly detection in data pipelines may be baked in.
- Cross-cloud / Hybrid Multi-cloud Support
Ability to replicate data not just to GCP but to other clouds or on-prem systems.
- Tighter Coupling with Vertex AI & Analytics
Data ingested via Datastream may more naturally flow into ML pipelines, embedding extraction, and RAG systems.
- User-driven enhancements
As more customers use it, Google is refining UI tooling, UX, connectors, and easier setup paths.
Project References for Google Datastream
Frequently Asked Questions of Google Datastream
Q1: Does Datastream require Dataflow?
Not strictly. Datastream can by itself replicate data to destinations like BigQuery or Cloud Storage. However, if you want custom transformations, enrichment, or filtering, Dataflow templates may be used in conjunction.
Q2: What is the pricing model for Datastream?
You pay based on data processed (GBs of change data + backfill). Additional downstream services (e.g., Dataflow, BigQuery, storage) incur their own costs.
Q3: Is the replication “exactly-once”?
Typically, Datastream offers at-least-oncesemantics, which means duplicates may occur; you need deduplication logic downstream if needed.
Q4: How does it handle schema changes?
Datastream can adapt to some schema evolutions (e.g. new columns). However, major changes (e.g. dropping columns) may require manual adjustments.
Q5: What latency can I expect?
Datastream is near real-time, but real latency depends on source system load, network, event size, throughput, and pipeline complexity. Some users report delays under ideal setup; others see minute-level lag.
Q6: Which source and destination databases are supported?
Sources: Oracle, MySQL, PostgreSQL, SQL Server, SaaS (various).
Destinations: BigQuery, Cloud Storage, Cloud SQL, Spanner.
Q7: Can I filter out certain tables or columns?
Yes — streams let you specify which tables to replicate and you can often exclude or filter columns to reduce data volume.
Q8: Can I cross projects / VPCs?
Yes, with VPC peering, private connectivity, or shared VPCs — though networking setup can be tricky. Many users raise connectivity issues across projects.
Q9: How reliable is it during large schema changes or high throughput?
It’s robust, but during schema tension (many structural changes) or sudden volume spikes, monitoring is necessary and occasional manual fixes may be required.
Third Eye Data’s take on Google Datastream
In today’s data-driven world, the ability to keep systems in sync — in real time — is a strategic advantage. Google Datastreamempowers organizations to move beyond rigid batch syncsand toward continuous data alignment, feeding analytics, ML, event systems, and hybrid architectures with live truths.
Yes, you’ll need to plan for latency, network configuration, schema evolution, and careful cost management. But the simplicity of serverless replication, integrated CDC + backfill, and seamless GCP integration make Datastream a compelling foundation for any modern data pipeline.
What You Should Do Next
- Enable Datastream in your GCP projectand create a small demo: replicate a table from your existing MySQL or PostgreSQL instance to BigQuery.
- Use Dataflow templates(Datastream → BigQuery) to pipe change events and validate correctness.
- Experiment with schema changes(add/remove columns) to see how Datastream adapts.
- Measure latencyend to end (source → destination) to understand your real-time behavior.
- Filter / exclude columns or tablesto reduce cost and noise.
- Integrate with downstream analytics / MLso your replicated data becomes immediately useful.
Once you see your live database changes reflected in analytics or dashboards reliably, you’ve unlocked a new level of data trust and agility.
We believe Datastream has potential in complex data ingestion & synchronization pipelines where low-latency updatesare needed. If clients request real-time ingestion from legacy DBs to data warehouses, integrating Datastream + Dataflow + BigQuery is a stack we would strongly consider.