Understanding the Power of Support Vector Machines
Have you ever wondered how a machine can look at an image and decide — “That’s a cat, not a dog”?
Or how your email automatically filters spam from your inbox without you ever marking it manually?
Behind many of these intelligent systems lies a powerful, mathematically elegant algorithm — the Support Vector Machine, or simply, SVM.

Once a cornerstone of classical machine learning, SVMs still hold their ground even in the age of deep learning. Their precision, efficiency, and theoretical soundness make them one of the most respected tools in a data scientist’s arsenal.
In this in-depth article, we’ll explore how SVMs work, where they’re used, their strengths and weaknesses, modern relevance, and industry insights — all crafted in a storytelling, blog-friendly tone that connects theory with real-world impact.
SVM Overview
What Is an SVM?
Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. Its primary goal is to find the best boundary (or hyperplane) that separates data points of different classes with the maximum possible margin.
In simpler terms, imagine drawing a line between red and blue dots on paper — your goal is to draw it such that it’s as far away from both colors as possible. That’s what SVM does — it finds that perfect dividing line.
A Glimpse into Its History
SVM was introduced in the 1990s by Vladimir Vapnik and Corinna Cortes, revolutionizing the world of statistical learning. Long before neural networks became mainstream, SVMs dominated tasks like text classification, image recognition, and bioinformatics, setting the foundation for many modern algorithms.
How Does SVM Work? (The Science Behind the Algorithm)
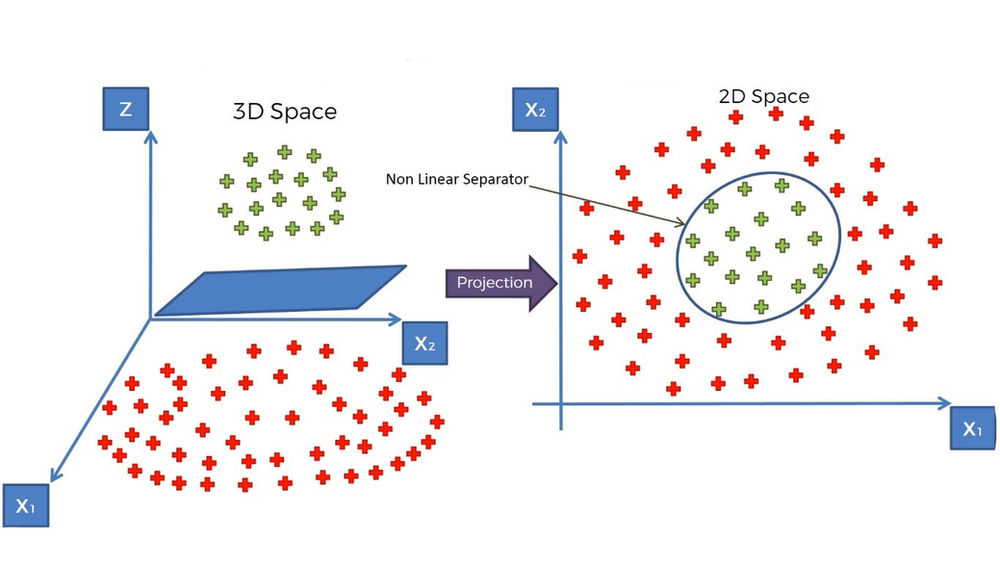
Image Courtesy: Codersarts
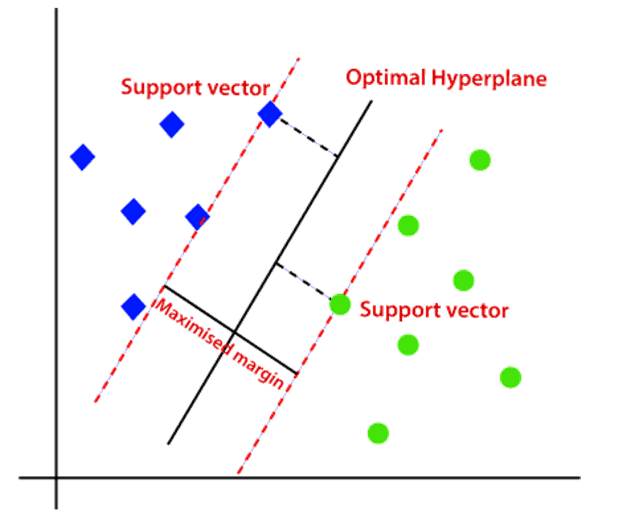
Image Courtesy: nomidl
To understand SVM, let’s break it down intuitively:
1. Separating Data with a Hyperplane
SVM works by finding a hyperplane (a decision boundary) that separates data points belonging to different classes.
In a 2D space, it’s just a line.
In 3D, it’s a plane.
In higher dimensions, it’s a hyperplane.
But among all possible boundaries, SVM chooses the one that maximizes the margin — i.e., the distance between the hyperplane and the nearest data points from each class.
2. Mathematical Perspective
If we denote:
- www as the weight vector (defining the orientation of the hyperplane)
- bbb as the bias term
Then the equation of the hyperplane is:
w⋅x+b=0w \cdot x + b = 0w⋅x+b=0
SVM tries to maximize the margin:
Margin=2∣∣w∣∣\text{Margin} = \frac{2}{||w||}Margin=∣∣w∣∣2
subject to the constraint that all points are correctly classified:
yi(w⋅xi+b)≥1y_i (w \cdot x_i + b) \geq 1yi (w⋅xi +b)≥1
This optimization problem is solved using techniques like Quadratic Programming, ensuring the most stable separation.
3. The Kernel Trick
What happens when the data isn’t linearly separable?
That’s where the magic of SVM truly begins.
SVM uses a kernel function to project the data into a higher-dimensional space where separation becomes possible.
Common kernel types include:
- Linear Kernel – For linearly separable data.
- Polynomial Kernel – Handles more complex, curved boundaries.
- Radial Basis Function (RBF) – Ideal for non-linear relationships.
- Sigmoid Kernel – Similar to neural network activation functions.
This ability to “bend reality” without explicitly computing transformations makes SVM both flexible and powerful.
4. Soft Margin vs. Hard Margin
- Hard Margin SVM: Strictly separates classes with no misclassification — works well for clean data.
- Soft Margin SVM: Allows some misclassifications to handle noisy or overlapping data — more realistic for real-world use.
Image Courtesy: researchgate
Use Cases / Problem Statements Solved with SVM
SVMs have stood the test of time, proving their reliability across industries. Let’s explore where they shine:
1. Healthcare and Bioinformatics
SVMs are heavily used in disease classification and medical diagnostics because of their robustness with high-dimensional data (like genetic datasets).
Example:
- Classifying tumors as malignant or benign using the Breast Cancer Wisconsin dataset.
- Detecting patterns in DNA microarray data for gene expression analysis.
SVMs handle these small yet feature-rich datasets exceptionally well — a reason why they’re still preferred in medical AI.
2. Financial Sector – Fraud Detection
Banks and fintech firms deploy SVMs for credit scoring, loan risk analysis, and fraud detection.
They can detect outliers and anomalies — transactions that deviate from normal patterns — with high accuracy.
Example:
An SVM model trained on past credit card transactions can predict suspicious behavior, reducing fraud losses by millions.
3. Text and Email Classification
From spam detection to sentiment analysis, SVMs were among the first models used in Natural Language Processing (NLP) before deep learning took over.
Example:
- Classifying emails into spam/non-spam categories.
- Analyzing social media posts for positive or negative sentiment.
Their efficiency in handling sparse data (like word frequency vectors) makes them ideal for text-based tasks.
4. Image Recognition and Object Detection
SVMs have powered early computer vision systems, including face detection, handwriting recognition, and object classification.
Example:
The famous HOG (Histogram of Oriented Gradients) + SVM pipeline was used in detecting pedestrians and faces before CNNs dominated the field.
5. Industrial Automation and Quality Control
In manufacturing, SVMs classify products based on sensor readings and detect defective items in production lines — improving quality and reducing costs.
6. Cybersecurity and Intrusion Detection
SVMs help classify network traffic into “normal” or “attack” patterns, identifying potential breaches or malware behaviors.
They remain one of the most reliable models for anomaly detection.
Pros of Using SVM
- High Accuracy and Robustness – Performs exceptionally well in complex classification tasks, even with limited data.
- Effective in High-Dimensional Spaces – Works great when the number of features is greater than the number of samples.
- Versatile Kernel Functions – Can handle both linear and non-linear data efficiently.
- Memory Efficient – Uses only support vectors, not all data points, in decision-making.
- Strong Theoretical Foundation – Built on solid mathematical optimization principles.
Cons and Limitations of SVM
- Computationally Intensive – Training time increases with large datasets.
- Difficult Parameter Tuning – Choosing the right kernel, C (penalty parameter), and gamma can be tricky.
- Less Interpretable – Unlike decision trees, SVMs don’t offer easy interpretability.
- Performance Drops with Noisy Data – Outliers can heavily influence results.
- Not Ideal for Large-Scale, Real-Time Tasks – Deep learning models often outperform SVMs in such cases.
Alternatives to SVM
While SVM remains relevant, several other algorithms often serve as alternatives:
- Logistic Regression – Simpler and faster for linear problems.
- Random Forests – More interpretable and robust to outliers.
- K-Nearest Neighbors (KNN) – Easy to implement but less scalable.
- Neural Networks – More suitable for large, unstructured data like images or speech.
- Naïve Bayes – Efficient for text classification with probabilistic assumptions.
Each alternative brings unique strengths, and sometimes hybrid approaches combine them for better performance.
Upcoming Updates / Industry Insights of SVM
1. SVM in Hybrid AI Systems
SVMs are increasingly integrated with deep learning for feature extraction and classification — known as Deep SVMs.
2. Quantum SVM (QSVM)
Researchers are exploring quantum computing to speed up the optimization process of SVMs, especially for massive datasets.
3. AutoML and SVM Optimization
Tools like Google AutoML and H2O.ai now automate kernel selection and hyperparameter tuning for SVMs, making them more accessible to non-experts.
4. SVM for Edge and IoT Devices
Due to their lightweight structure, SVMs are being deployed on embedded systems for real-time classification tasks like gesture or anomaly detection.
Project References
Frequently Asked Questions on SVM
Q1. Is SVM a supervised or unsupervised algorithm?
SVM is a supervised learning algorithm — it requires labeled data for training.
Q2. Can SVM be used for regression tasks?
Yes! The Support Vector Regression (SVR) variant extends SVM for predicting continuous values.
Q3. How do I choose the right kernel?
Start simple:
- Use linear for linearly separable data.
- Try RBF or polynomial for complex relationships.
Use cross-validation to compare performance.
Q4. How is SVM different from logistic regression?
SVM focuses on maximizing the margin between classes, while logistic regression focuses on maximizing the probability of class membership.
Q5. Is SVM still relevant in 2025?
Absolutely. While deep learning dominates unstructured data, SVMs remain the go-to choice for structured, tabular, and small-to-medium datasets.
Third Eye Data’s Take on SVM
We see SVM (Support Vector Machine)as a valuable model for boundary-sensitive classification tasks—especially when you have limited or balanced datasets with complex class separability. At Third Eye Data, we include SVMs in our modeling toolkit, using them as a complementary or alternative model depending on dataset size, feature space, and performance trade-offs.
Support Vector Machines may not be the newest buzzword in machine learning, but they remain a symbol of precision, efficiency, and mathematical beauty.
They teach us that sometimes, the simplest geometric intuition — a line separating points — can power some of the most intelligent systemson the planet.
In an age where neural networks grab headlines, SVMs quietly continue to drive medical breakthroughs, detect financial frauds, secure networks, and simplify classification problemsacross industries.
Call to Action
Want to get your hands dirty with SVM?
Start simple:
- Load a dataset (like the Iris dataset) in Python
- Use Scikit-learn’s SVC()
- Experiment with kernels — linear, polynomial, RBF
- Visualize your decision boundaries
You’ll witness firsthand how elegantly SVM separates data — and perhaps, you’ll understand why it remains one of the most beautifully engineered algorithms in machine learning history.






