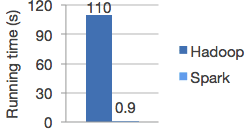
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports acyclic data flow and in-memory computing.
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
text_file = spark.textFile(“hdfs://…”)
text_file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
Combine SQL, streaming, and complex analytics.
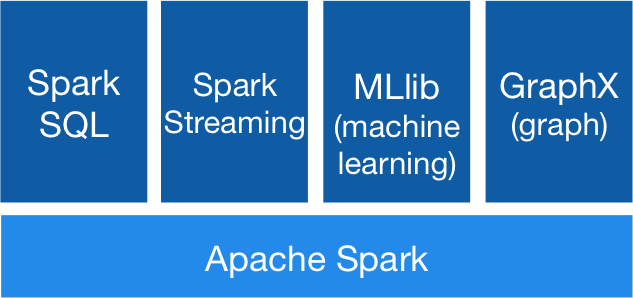
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, or on Apache Mesos. Access data in HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source.
In comparison to MapReduce and other Apache Hadoop components, the Apache Spark API is very friendly to developers, hiding much of the complexity of a distributed processing engine behind simple method calls. The canonical example of this is how almost 50 lines of MapReduce code to count words in a document can be reduced to just a few lines of Apache Spark (here shown in Scala):
val textFile = sparkSession.sparkContext.textFile(“hdfs:///tmp/words”) val counts = textFile.flatMap(line => line.split(“ “)) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile(“hdfs:///tmp/words_agg”)
By providing bindings to popular languages for data analysis like Python and R, as well as the more enterprise-friendly Java and Scala, Apache Spark allows everybody from application developers to data scientists to harness its scalability and speed in an accessible manner.
At the heart of Apache Spark is the concept of the Resilient Distributed Dataset (RDD), a programming abstraction that represents an immutable collection of objects that can be split across a computing cluster. Operations on the RDDs can also be split across the cluster and executed in a parallel batch process, leading to fast and scalable parallel processing.
RDDs can be created from simple text files, SQL databases, NoSQL stores (such as Cassandra and MongoDB), Amazon S3 buckets, and much more besides. Much of the Spark Core API is built on this RDD concept, enabling traditional map and reduce functionality, but also providing built-in support for joining data sets, filtering, sampling, and aggregation.
Spark runs in a distributed fashion by combining a driver core process that splits a Spark application into tasks and distributes them among many executor processes that do the work. These executors can be scaled up and down as required for the application’s needs.
Originally known as Shark, Spark SQL has become more and more important to the Apache Spark project. It is likely the interface most commonly used by today’s developers when creating applications. Spark SQL is focused on the processing of structured data, using a dataframe approach borrowed from R and Python (in Pandas). But as the name suggests, Spark SQL also provides a SQL2003-compliant interface for querying data, bringing the power of Apache Spark to analysts as well as developers.
Alongside standard SQL support, Spark SQL provides a standard interface for reading from and writing to other datastores including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet, all of which are supported out of the box. Other popular stores—Apache Cassandra, MongoDB, Apache HBase, and many others—can be used by pulling in separate connectors from the Spark Packages ecosystem.
Selecting some columns from a dataframe is as simple as this line:
citiesDF.select(“name”, “pop”)
Using the SQL interface, we register the dataframe as a temporary table, after which we can issue SQL queries against it:
citiesDF.createOrReplaceTempView(“cities”) spark.sql(“SELECT name, pop FROM cities”)
Behind the scenes, Apache Spark uses a query optimizer called Catalyst that examines data and queries in order to produce an efficient query plan for data locality and computation that will perform the required calculations across the cluster. In the Apache Spark 2.x era, the Spark SQL interface of dataframes and datasets (essentially a typed dataframe that can be checked at compile time for correctness and take advantage of further memory and compute optimizations at run time) is the recommended approach for development. The RDD interface is still available, but is recommended only if you have needs that cannot be encapsulated within the Spark SQL paradigm.
Apache Spark also bundles libraries for applying machine learning and graph analysis techniques to data at scale. Spark MLlib includes a framework for creating machine learning pipelines, allowing for easy implementation of feature extraction, selections, and transformations on any structured dataset. MLLib comes with distributed implementations of clustering and classification algorithms such as k-means clustering and random forests that can be swapped in and out of custom pipelines with ease. Models can be trained by data scientists in Apache Spark using R or Python, saved using MLLib, and then imported into a Java-based or Scala-based pipeline for production use.
Note that while Spark MLlib covers basic machine learning including classification, regression, clustering, and filtering, it does not include facilities for modeling and training deep neural networks (for details see InfoWorld’s Spark MLlib review). However, Deep Learning Pipelines are in the works.
Spark GraphX comes with a selection of distributed algorithms for processing graph structures including an implementation of Google’s PageRank. These algorithms use Spark Core’s RDD approach to modeling data; the GraphFrames package allows you to do graph operations on dataframes, including taking advantage of the Catalyst optimizer for graph queries.
Spark Streaming was an early addition to Apache Spark that helped it gain traction in environments that required real-time or near real-time processing. Previously, batch and stream processing in the world of Apache Hadoop were separate things. You would write MapReduce code for your batch processing needs and use something like Apache Storm for your real-time streaming requirements. This obviously leads to disparate codebases that need to be kept in sync for the application domain despite being based on completely different frameworks, requiring different resources, and involving different operational concerns for running them.
Spark Streaming extended the Apache Spark concept of batch processing into streaming by breaking the stream down into a continuous series of microbatches, which could then be manipulated using the Apache Spark API. In this way, code in batch and streaming operations can share (mostly) the same code, running on the same framework, thus reducing both developer and operator overhead. Everybody wins.
A criticism of the Spark Streaming approach is that microbatching, in scenarios where a low-latency response to incoming data is required, may not be able to match the performance of other streaming-capable frameworks like Apache Storm, Apache Flink, and Apache Apex, all of which use a pure streaming method rather than microbatches.
Structured Streaming (added in Spark 2.x) is to Spark Streaming what Spark SQL was to the Spark Core APIs: A higher-level API and easier abstraction for writing applications. In the case of Structure Streaming, the higher-level API essentially allows developers to create infinite streaming dataframes and datasets. It also solves some very real pain points that users have struggled with in the earlier framework, especially concerning dealing with event-time aggregations and late delivery of messages. All queries on structured streams go through the Catalyst query optimizer, and can even be run in an interactive manner, allowing users to perform SQL queries against live streaming data.
Structured Streaming is still a rather new part of Apache Spark, having been marked as production-ready in the Spark 2.2 release. However, Structured Streaming is the future of streaming applications with the platform, so if you’re building a new streaming application, you should use Structured Streaming. The legacy Spark Streaming APIs will continue to be supported, but the project recommends porting over to Structured Streaming, as the new method makes writing and maintaining streaming code a lot more bearable.
While Structured Streaming provides high-level improvements to Spark Streaming, it currently relies on the same microbatching scheme of handling streaming data. However, the Apache Spark team is working to bring continuous streaming without microbatching to the platform, which should solve many of the problems with handling low-latency responses (they’re claiming ~1ms, which would be very impressive). Even better, because Structured Streaming is built on top of the Spark SQL engine, taking advantage of this new streaming technique will require no code changes.
In addition improving streaming performance, Apache Spark will be adding support for deep learning via Deep Learning Pipelines. Using the existing pipeline structure of MLlib, you will be able to construct classifiers in just a few lines of code, as well as apply custom Tensorflow graphs or Keras models to incoming data. These graphs and models can even be registered as custom Spark SQL UDFs (user-defined functions) so that the deep learning models can be applied to data as part of SQL statements.
Neither of these features is anywhere near production-ready at the moment, but given the rapid pace of development we’ve seen in Apache Spark in the past, they should be ready for prime time in 2018.
Source: Apache Spark™ – Lightning-Fast Cluster Computing
Source: What is Apache Spark? The big data analytics platform explained | InfoWorld

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.