Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. By using these frameworks and related open-source projects, such as Apache Hive and Apache Pig, you can process data for analytics purposes and business intelligence workloads. Additionally, you can use Amazon EMR to transform and move large amounts of data into and out of other AWS data stores and databases, such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
If you are a first-time user of Amazon EMR, we recommend that you begin by reading the following:
In This Section
This topic provides an overview of Amazon EMR clusters, including how to submit work to a cluster, how that data is processed, and the various states that the cluster goes through during processing.
In This Topic
The central component of Amazon EMR is the cluster. A cluster is a collection of Amazon Elastic Compute Cloud (Amazon EC2) instances. Each instance in the cluster is called a node. Each node has a role within the cluster, referred to as the node type. Amazon EMR also installs different software components on each node type, giving each node a role in a distributed application like Apache Hadoop.
The node types in Amazon EMR are as follows:
When you run your cluster on Amazon EMR, you have several options as to how you specify the work that needs to be done.
When you launch your cluster, you choose the frameworks and applications to install for your data processing needs. There are two ways to process data in your Amazon EMR cluster: by submitting jobs or queries directly to the applications that are installed on your cluster or by running steps in the cluster.
You can submit jobs and interact directly with the software that is installed in your Amazon EMR cluster. To do this, you typically connect to the master node over a secure connection and access the interfaces and tools that are available for the software that runs directly on your cluster. For more information, see Connect to the Cluster.
You can submit one or more ordered steps to an Amazon EMR cluster. Each step is a unit of work that contains instructions to manipulate data for processing by software installed on the cluster.
The following is an example process using four steps:
Generally, when you process data in Amazon EMR, the input is data stored as files in your chosen underlying file system, such as Amazon S3 or HDFS. This data passes from one step to the next in the processing sequence. The final step writes the output data to a specified location, such as an Amazon S3 bucket.
Steps are run in the following sequence:
The following diagram represents the step sequence and change of state for the steps as they are processed.

If a step fails during processing, its state changes to TERMINATED_WITH_ERRORS. By default, any remaining steps in the sequence are set to CANCELLED and do not run, although you can choose to ignore processing failures and allow remaining steps to proceed.
The following diagram represents the step sequence and default change of state when a step fails during processing.

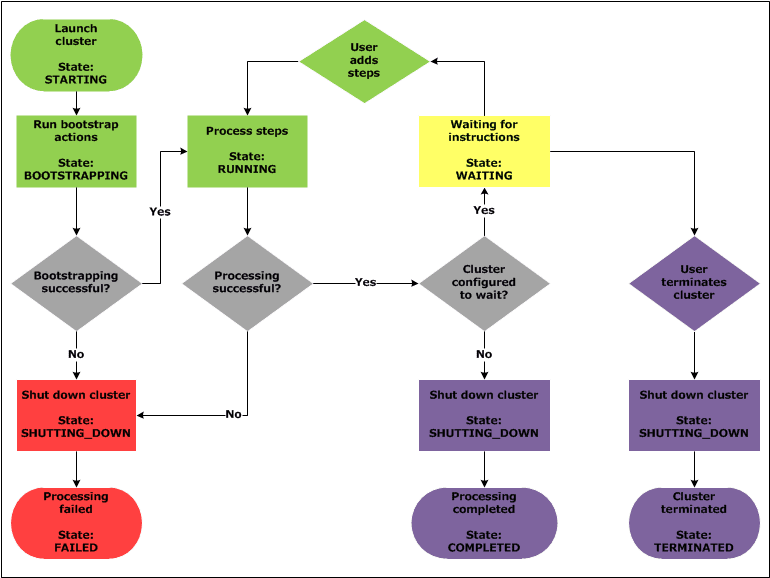
A successful Amazon EMR cluster follows this process:
STARTINGBOOTSTRAPPINGRUNNING The cluster sequentially runs all steps during this phase.WAITING state or aSHUTTING_DOWN state, described as follows.
WAITING state after processing all submitted steps and wait for the next set of instructions. If you have more data to process, you can add more steps. You must manually terminate a long-running cluster when you no longer need it. After you manually terminate the cluster, it goes into the stateSHUTTING_DOWN and then into the stateTERMINATED.SHUTTING_DOWN after all of the steps complete. The instances are terminated, and all data stored in the cluster itself is deleted. Information stored in other locations, such as in your Amazon S3 bucket, persists. When the shutdown process completes, the cluster state is set to.COMPLETEDA failure during the clustering process terminates the cluster and all of its instances unless: a) you enable termination protection; or b) you supply an ActionOnFailure in the StepConfig for the step. Any data stored on the cluster is deleted. The cluster state is set toTERMINATED_WITH_ERRORS. If you have enabled termination protection so that you can retrieve data from your cluster in the event of a failure, then the cluster is not terminated. Once you are truly done with the cluster, you can remove termination protection and terminate the cluster. For more information, see Managing Cluster Termination.
The following diagram represents the lifecycle of a cluster, and how each stage of the lifecycle maps to a particular cluster state.
Amazon EMR service architecture consists of several layers, each of which provides certain capabilities and functionality to the cluster. This section provides an overview of the layers and the components of each.
The storage layer includes the different file systems that are used with your cluster. There are several different types of storage options as follows.
Hadoop Distributed File System (HDFS) is a distributed, scalable file system for Hadoop. HDFS distributes the data it stores across instances in the cluster, storing multiple copies of data on different instances to ensure that no data is lost if an individual instance fails. HDFS is ephemeral storage that is reclaimed when you terminate a cluster. HDFS is useful for caching intermediate results during MapReduce processing or for workloads that have significant random I/O.
For more information, go to HDFS Users Guide on the Apache Hadoop website.
Using the EMR File System (EMRFS), Amazon EMR extends Hadoop to add the ability to directly access data stored in Amazon S3 as if it were a file system like HDFS. You can use either HDFS or Amazon S3 as the file system in your cluster. Most often, Amazon S3 is used to store input and output data and intermediate results are stored in HDFS.
The local file system refers to a locally connected disk. When you create a Hadoop cluster, each node is created from an Amazon EC2 instance that comes with a preconfigured block of pre-attached disk storage called an instance store. Data on instance store volumes persists only during the lifecycle of its Amazon EC2 instance.
The resource management layer is responsible for managing cluster resources and scheduling the jobs for processing data.
By default, Amazon EMR uses YARN (Yet Another Resource Negotiator), which is a component introduced in Apache Hadoop 2.0 to centrally manage cluster resources for multiple data-processing frameworks. However, there are other frameworks and applications that are offered in Amazon EMR that do not use YARN as a resource manager. Amazon EMR also has an agent on each node that administers YARN components, keeps the cluster healthy, and communicates with the Amazon EMR service.
The data processing framework layer is the engine used to process and analyze data. There are many frameworks available that run on YARN or have their own resource management. Different frameworks are available for different kinds of processing needs, such as batch, interactive, in-memory, streaming, and so on. The framework that you choose depends on your use case. This impacts the languages and interfaces available from the application layer, which is the layer used to interact with the data you want to process. The main processing frameworks available for Amazon EMR are Hadoop MapReduce and Spark.
Hadoop MapReduce is an open-source programming model for distributed computing. It simplifies the process of writing parallel distributed applications by handling all of the logic, while you provide the Map and Reduce functions. The Map function maps data to sets of key-value pairs called intermediate results. The Reduce function combines the intermediate results, applies additional algorithms, and produces the final output. There are multiple frameworks available for MapReduce, such as Hive, which automatically generates Map and Reduces programs.
For more information, go to How Map and Reduce operations are actually carried out on the Apache Hadoop Wiki website.
Spark is a cluster framework and programming model for processing big data workloads. Like Hadoop MapReduce, Spark is an open-source, distributed processing system but uses directed acyclic graphs for execution plans and in-memory caching for datasets. When you run Spark on Amazon EMR, you can use EMRFS to directly access your data in Amazon S3. Spark supports multiple interactive query modules such as SparkSQL.
For more information, see Apache Spark on Amazon EMR Clusters in the Amazon EMR Release Guide.
Amazon EMR supports many applications, such as Hive, Pig, and the Spark Streaming library to provide capabilities such as using higher-level languages to create processing workloads, leveraging machine learning algorithms, making stream processing applications, and building data warehouses. In addition, Amazon EMR also supports open-source projects that have their own cluster management functionality instead of using YARN.
You use various libraries and languages to interact with the applications that you run on Amazon EMR. For example, you can use Java, Hive, or Pig with MapReduce or Spark Streaming, Spark SQL, MLlib, and GraphX with Spark.
Source: What Is Amazon EMR? – Amazon EMR

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.