BI EVOLUTION: INCREMENTAL DATA REFRESH
As Power BI grows to become a superset of Analysis Services functionality, a lot of that functionality will evolve as it becomes available. Incremental data refresh is a great example of how Power BI is modernizing/simplifying complex BI implementations. Incremental data refresh is the process of incrementally loading new or changed data to a BI model without needing to reload the full set of data. This can have the following benefits:
- Refreshes are faster since you don’t need to load all the data every time and more can be done in parallel. This allows for new data to be added quickly.
- Less memory may be used during processing (again because you are only loading part of the data)
- Models can grow to very large sizes.
- Old data can be dropped when not needed.
- Existing data can be updated without updating the entire model.
- Refreshes may be more reliable.
People have been able to achieve incremental data refresh with Analysis Services since its inception 20 years ago by leveraging partitions. Partitions divide a table into logical partition objects each with its own query that is used to pull data from a data source. Each partition can be processed, reprocessed or deleted independently of the rest of the objects in the model. By setting the filter conditions of the source queries differently for each partition, they will each load a different set of data.

Partitioning is an effective way of implementing incremental data refresh. Partitions can be added/deleted/updated manually through SQL Server Management Studio. This can also be achieved programmatically by using TMSL scripts or by writing code with AMO. Writing code would be the primary way that someone would incrementally load data into their model. For example, if we had a data warehouse in SQL which received new data every single day and we had an Analysis Services model which also needed to show that data, we could write code that was part of the same ETL process which loaded the data warehouse. We would add steps to the end of that ETL which could create or update existing partitions in the model to reflect the new data.
Writing code can be complicated especially if you haven’t done it before (and even if you have). Setting up incremental processing for Analysis Services takes up a large chunk of my resume as it does for many BI professionals. Over the years, we have tried to make this simpler by providing examples along with code samples. The complexity is still there however, and it was the number one blocker that I would hear from Power BI customers when their models outgrew the size limits of Power BI and they needed to switch to Analysis Services.
Processing data in Power BI has always been simpler than with Analysis Services. The UI allows you to configure a scheduled refresh so that no code is required to see the most up to date data when you need it. Another reason that is has been simpler is that it didn’t used to support incremental refresh which would force you to reload all the data on each refresh. Reloading all the data removes a lot of the challenges of keeping the data in the model in sync with the data at the source as it will naturally pick up all changes which happened.
A full refresh is always the simplest option and should be used whenever possible. Unfortunately, as your data volumes grow, so does complexity and it may become impractical to do a full refresh every time new data is added. Power BI Premium does now allow for large models as we increased its dataset size limits to 10 GB (after compression) and we plan to completely remove the limit in the future. When we enabled incremental refresh for Power BI (now in preview), we wanted to make sure that we kept things as simple as possible so that a user did not need to learn a whole bunch of new tools or learn how to write a bunch of complex code simply because their data got larger. We also wanted to make sure that we kept incremental refresh powerful as well as flexible. Incremental processing can be done differently by every organization which we needed to account for. Therefore, we introduced a concept called refresh policies. Refresh policies are additional metadata on a table which allows the modeler to specify how data should be loaded into that table. This means that each table will contain the knowledge of how to load itself so that when the Power BI scheduler or an API call triggered by the ETL process kicks off a refresh, data can be loaded properly. The process which triggers the refresh does not need to know anything about the data itself or maintain any state about the model. Each table will automatically figure out what, if anything, it needs to do based on the policy. Policies contain information on how much data should be retained, which already processed data could still potentially change, when the current period ends, a watermark column that can be used to check if data has changed and several other properties.
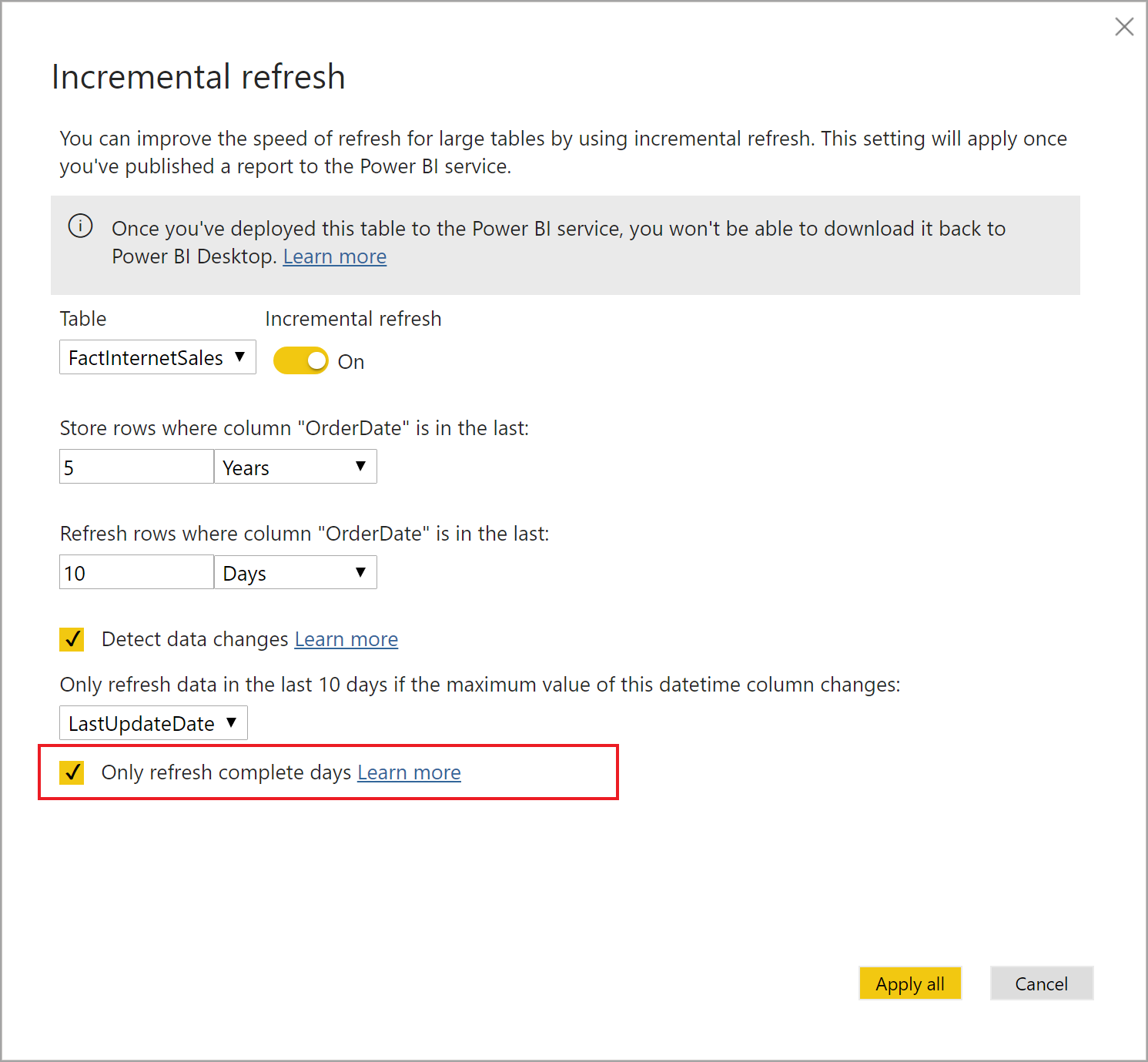
Incremental refresh policies can be authored in the Power BI Desktop. Authoring of the model can occur on a subset of the full dataset. Once the dataset is loaded to the Power BI service and the first refresh as completed, the full dataset (according to the refresh policy) will become available. Note that refresh policies are only available in Power BI Premium currently. We do have plans to extend them to Power BI shared capacity.
Power BI becoming a superset of Analysis Services functionality does mean that it will also gain partitioning functionality. However, refresh policies are an evolution of 20 years of experience gained from Analysis Services. Internally, refresh policies still leverage partitioning to implement incremental processing. Model authors no longer need to write complex code to manage the state of data in order to keep in in sync with the source. They no longer need to worry about data compression issues and poor performance caused by having too many small partitions. Power BI will automatically handle merging partitions in order to get the best possible data compression while still achieving the requirements of the refresh policy. As BI evolves, BI professionals, can spend less time worrying about these things and more time adding business value for their organizations.
Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.


