AI is no longer just an idea; it’s becoming a thinker and decision-maker, making Alan Turing’s dream a reality. With Moore’s Law still holding and hardware advancing rapidly, AI’s potential grows, but it’s only as good as the data it’s fed.
According to S&P Global Market Research, businesses scrapping most of their AI initiatives increased to 42% this year, up from 17% last year. Shockingly, around 91% of organizations report that poor data quality and governance directly impacts business performance and that is why they drop their AI initiatives.
So, clean, well-governed data is now essential for successful AI initiatives.
In this series of articles, we’ll explore Enterprise Data Governance use cases. We will also focus on AI governance itself in our next series. We covered the essence of Enterprise MDM in our previous Use Case in this series. You can refer to it.
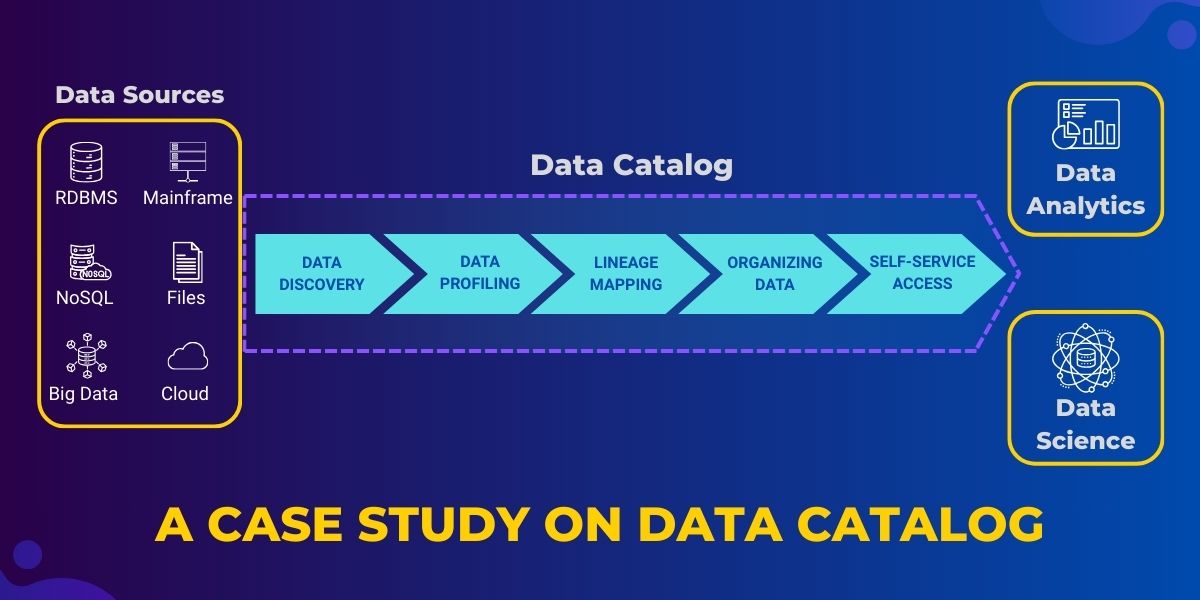
Today we will cover one of my favorite topics, Data Catalog. Data Management (DM) and Data Organizations (DO) are two aspects in IT. We have been doing amazing in DM, but we can focus more on DO. In the era of thinking machines, we can confuse decision-making AI systems with poor DO.
Once, I got a call from the CXOs of a big multinational food company. They were in a blind. Their supply chain costs for a few product lines were spiraling out of control. The CIO had a clear goal: find a way to cut those costs. She knew the first step was to gather the right people. So, she called in the analytics management officers.
But as we dug into the problem, we quickly realized something. The company’s supply chain was a maze, too many moving parts. Data wasn’t being captured at all the right points. It wasn’t being captured, stored or reported in a way that made sense.
Each department, sourcing, logistics, inventory management—had its own set of data and reports. There was no unified view of the performance or tracking measures. The metrics were stuck in silos. Each department controlled its own data. Reports, metrics taxonomies didn’t match. Sounds familiar?
They had a centralized system, a data lake, but it wasn’t enough. The reports were locked in the hands of IT, far from the decision-makers.
They were managing Information, but they were not organizing the information. Data governance was missing.
Enterprise data cataloging was the solution. It is a discipline Product managers must emphasize in any business when a product line even starts. It is just not about cataloging it once in the beginning but implementing an ownership model, maintenance processes and accessibility methods for the business stakeholders must be set up. The catalog must cover the entire journey of the product in the supply chain process.
Without a data catalog, enterprises may face several pitfalls, including:
Lack of access to an enterprise Data catalog with the Single Version of the Truth for each common Metrics can delay decision-making, leading to missed opportunities, lost sales, and inefficiencies in customer service and product development. For a $100 Million company (revenue per year), the cost per year could be from a million to $5 Million of cost). For my client, she actually had to have individual meetings with various departments first to even understand the locations of the data. Enterprise Data Lake was just not enough.
Inconsistent metrics across departments can cause confusions in reporting, analytics, and decision-making, leading to poor strategic choices and financial mismanagement. For a $100 Million company (revenue per year, the cost per year could be from a million to $5 Million of cost) as well. Cost per transactions and cost per activity are two different metrics and can not be compared.
Time spent searching for data rather than performing valuable analysis leads to decreased productivity and a slower time-to-market for new products . Analysts, data scientists, AI scientists or even CXOs spend more than 30% of their time looking for the data alone. This could amount to millions of dollars annually depending on the size of the organization.
Without a Data Catalog at enterprise level without a consolidated KPI list, the company will run mainly based on confusions on past performances. Maintaining siloed Metrics will double or triple the cost. Without information management, data quality can drop and if not handled, it leads to chaos. Errors, inefficiencies around faulty data will surely lead to growth of the business itself. This will surely lead to millions of dollars of extra cost, even for a smaller organization.
Without a data catalog, quarterly or annual audits for compliance will take forever. Unnecessarily many employees got to get involved. Cost rises and time taken would be extensive. Auditor has to deal with confusions and a hairy situation which leads to frustrations. At times, even explanations for some expenses could be missing or be unsure to locate the right metrics. This can lead to compliances risks. For example, if a customer asks to do data deletion and there is no catalog metrics for identifying those users, this can lead to Data Deletion violation act, GDPR, CCPA or even HIPAA compliance. Penalties of missing compliances could be up to 4% of the annual revenue.
Poor data management reduces collaboration between teams, leading to missed innovation opportunities, project delays, and poor customer outcomes.
Companies can boost their productivity by 25% by improving collaboration, and organizations that fail to collaborate effectively may lose significant revenue growth potential.
According to various studies, poor data management and inefficiencies can lead to trillions of losses annually globally. Specific losses for individual companies depend on their size, industry, and data management practices, but even mid-sized businesses can face losses in the millions of dollars each year.
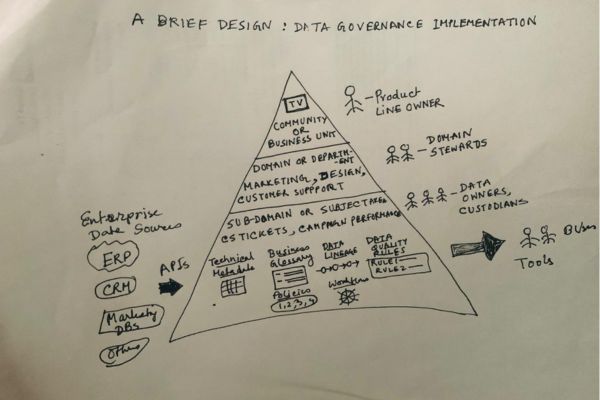
Many noted tools address data cataloging challenges by leveraging a structured approach that incorporates communities, domains, assets, workflows, and more. It is about breaking down a complex problem into smaller units of work. In a massive company with Billions of dollars revenue and based on the number of product lines that they have, cataloging could be at each product line level. In a smaller organization with less number of product lines with say $100 Million dollar revenue, it could be done at Enterprise subject area level like customer, product, transactions, etc. However, the problem is tackled, here is a common approach.

We create communities with a committee, where stakeholders such as data stewards, analysts, and business users can collaborate. These communities help align data definitions, governance practices, and ensure that everyone has a shared understanding of data assets. By promoting communication and transparency, decision makers can have access to approved metrics set globally at the enterprise level rather than at a data siloed level. A centralized portal for Data Governance, itself, can be very useful for collaborations.
We can set up subject areas based on the business functions like finance, marketing, or HR that are associated with particular data assets. This domain-centric approach helps organize data by business function, making it easier to govern and manage. Data stewards and owners can focus on their specific domains or subject areas, ensuring that data is well-governed, compliant, and high-quality.
We set up data assets like a data catalog, which organizes these assets with rich metadata, allowing users to quickly discover and understand their data. By tagging assets with key attributes, such as quality, compliance, and usage, it helps users easily locate and access the data they need, improving efficiency and decision-making.
We then streamline approval processes for data change management for data governance and stewardship. These workflows enable automated processes for managing data quality, ensuring compliance, and tracking changes in data assets. For example, when new data is ingested, workflows can trigger automatic checks for data quality or initiate approval processes for data access. Or additions of a KPI in a subject area must go through approval via an automated workflow for inclusions with a change log.
Assets must be accurately described. Gen AI can do a great job here. The AI also can help identify relationships between assets, providing a clearer understanding of how data is connected across domains.
As organizations grow and collect more data, a mature data catalog scales to handle increased volumes. Whether it’s adding new domains, managing more assets, or supporting additional workflows, an organized approach is set to scale with an organization’s data needs while maintaining governance and quality standards.
A trusted data catalog can be achieved for sure, and we would rather do this sooner than later. It will not only reduce OPEX but also reduce organizational stress, paving its path to creative endless growth.
Written By:
Aparajeeta Das
Co-Founder & CDO, ThirdEye Data



