What Is Amazon Kinesis Data Analytics?
With Amazon Kinesis Data Analytics, you can process and analyze streaming data using standard SQL. The service enables you to quickly author and runs powerful SQL code against streaming sources to perform time series analytics, feed real-time dashboards, and create real-time metrics.
To get started with Kinesis Data Analytics, you create a Kinesis data analytics application that continuously reads and processes streaming data. The service supports ingesting data from Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose streaming sources. Then, you author your SQL code using the interactive editor and test it with live streaming data. You can also configure destinations where you want Kinesis Data Analytics to send the results.
Kinesis Data Analytics supports Amazon Kinesis Data Firehose (Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service), AWS Lambda, and Amazon Kinesis Data Streams as destinations.
When Should I Use Amazon Kinesis Data Analytics?
Amazon Kinesis Data Analytics enables you to quickly author SQL code that continuously reads, processes, and stores data in near real time. Using standard SQL queries on the streaming data, you can construct applications that transform and provide insights into your data. Following are some of the example scenarios for using Kinesis Data Analytics:
- Generate time-series analytics – You can calculate metrics over time windows, and then stream values to Amazon S3 or Amazon Redshift through a Kinesis data delivery stream.
- Feed real-time dashboards – You can send aggregated and processed streaming data results downstream to feed real-time dashboards.
- Create real-time metrics – You can create custom metrics and triggers for use in real-time monitoring, notifications, and alarms.
Amazon Kinesis Data Analytics: How It Works
An application is a primary resource in Amazon Kinesis Data Analytics that you can create in your account. You can create and manage applications using the AWS Management Console or the Amazon Kinesis Data Analytics API. Kinesis Data Analytics provides API operations to manage applications. For a list of API operations, see Actions.
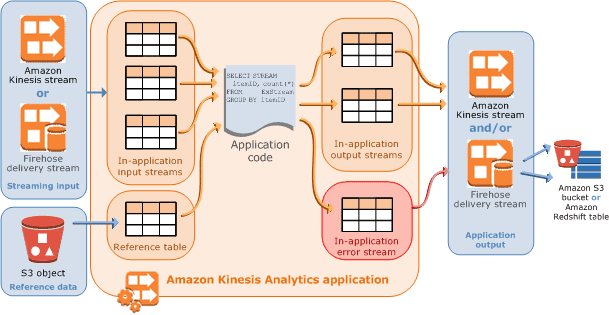
Amazon Kinesis data analytics applications continuously read and process streaming data in real time. You write application code using SQL to process the incoming streaming data and produce output. Then, Kinesis Data Analytics writes the output to a configured destination. The following diagram illustrates a typical application architecture.
Each application has a name, description, version ID, and status. Amazon Kinesis Data Analytics assigns a version ID when you first create an application. This version ID is updated when you update any application configuration. For example, if you add an input configuration, add or delete a reference data source, or add or delete output configuration, or update application code, Kinesis Data Analytics updates the current application version ID. Kinesis Data Analytics also maintains time stamps for when an application was created and last updated.
In addition to these basic properties, each application consists of the following:
- Input – The streaming source for your application. You can select either a Kinesis data stream or a Kinesis data delivery stream as the streaming source. In the input configuration, you map the streaming source to an in-application input stream. The in-application stream is like a continuously updating table upon which you can perform the SELECT and INSERT SQL operations. In your application code, you can create additional in-application streams to store intermediate query results.You can optionally partition a single streaming source in multiple in-application input streams to improve the throughput. For more information, see Limits and Configuring Application Input.Amazon Kinesis Data Analytics provides a timestamp column in each application stream called Timestamps and the ROWTIME Column. You can use this column in time-based windowed queries. For more information, see Windowed Queries.You can optionally configure a reference data source to enrich your input data stream within the application. It results in an in-application reference table. You must store your reference data as an object in your S3 bucket. When the application starts, Amazon Kinesis Data Analytics reads the Amazon S3 object and creates an in-application table. For more information, see Configuring Application Input.
- Application code – A series of SQL statements that process input and produce output. You can write SQL statements against in-application streams and reference tables, and you can write JOIN queries to combine data from both of these sources. In its simplest form, application code can be a single SQL statement that selects from a streaming input and inserts results into a streaming output. It can also be a series of SQL statements where the output of one feeds into the input of the next SQL statement. Further, you can write application code to split an input stream into multiple streams and then apply additional queries to process these streams. For more information, see Application Code.
- Output – In application code, query results go to in-application streams. In your application code, you can create one or more in-application streams to hold intermediate results. You can then optionally configure application output to persist data in the in-application streams, that hold your application output (also referred to as in-application output streams), to external destinations. External destinations can be a Kinesis data delivery stream or a Kinesis data stream. Note the following about these destinations:
- You can configure a Kinesis data delivery stream to write results to Amazon S3, Amazon Redshift, or Amazon Elasticsearch Service (Amazon ES).
- You can also write application output to a custom destination, instead of Amazon S3 or Amazon Redshift. To do that, you specify a Kinesis data stream as the destination in your output configuration. Then, you configure AWS Lambda to poll the stream and invoke your Lambda function. Your Lambda function code receives stream data as input. In your Lambda function code, you can write the incoming data to your custom destination. For more information, see Using AWS Lambda with Amazon Kinesis Data Analytics.
Source: What Is Amazon Kinesis Data Analytics? – Amazon Kinesis Data Analytics