Why Your AI Finally Understands You!?
Transformers for Semantic Embeddings
Introduction: Why Keywords Aren’tEnough Anymore
Imagine you’re shopping online and type “laptop with good battery for travel”into the search bar. Instead of showing you lightweight laptops with long-lasting batteries, the site shows results like “battery charger for laptops” or “laptop battery replacement.” Technically, the words match — but the intent is completely different.

Or think of a support query: You type “can’t log into my account”, but the system suggests articles titled “authentication error handling.”Both mean the same thing, yet the search engine fails to connect them.
This is the limitation of keyword-based search. Traditional systems focus on the exact words, not the meaning behind them. In today’s fast-paced, information-heavy world, that’s not enough. Users expect technology that understands them the way another person would.
That’s where transformers for semantic embeddingscome in. They’re the hidden engine behind modern AI applications — from chatbots and enterprise search to recommendation engines and Retrieval-Augmented Generation (RAG) systems. By converting words, sentences, or entire documents into mathematical vectors that actually capture meaning, these models allow machines to “get” context the way humans do.
What Exactly Are Semantic Embeddings?
Let’s break it down.
At a high level, semantic embeddingsare numerical representations of text (or images, or other data types) that capture the semantic meaningbehind them. Instead of just knowing that “login” and “authentication” are different words, embeddings place them close together in a high-dimensional space because they’re conceptually related.
This “semantic space” acts like a map of meaning:
- Words or phrases with similar meanings cluster together.
- Unrelated concepts remain far apart.
What makes embeddings so powerful today is the transformer architecture. Models like BERT, RoBERTa, and Sentence-Transformersleverage self-attention mechanisms to capture context. For instance, the word “bank” means one thing next to “river” and something entirely different next to “loan.” Transformers help embeddings recognize these nuances, something older models couldn’t achieve.
In simple terms: transformers allow machines to finally understand context the way humans do.
How the Transformer Embedding Process Works:
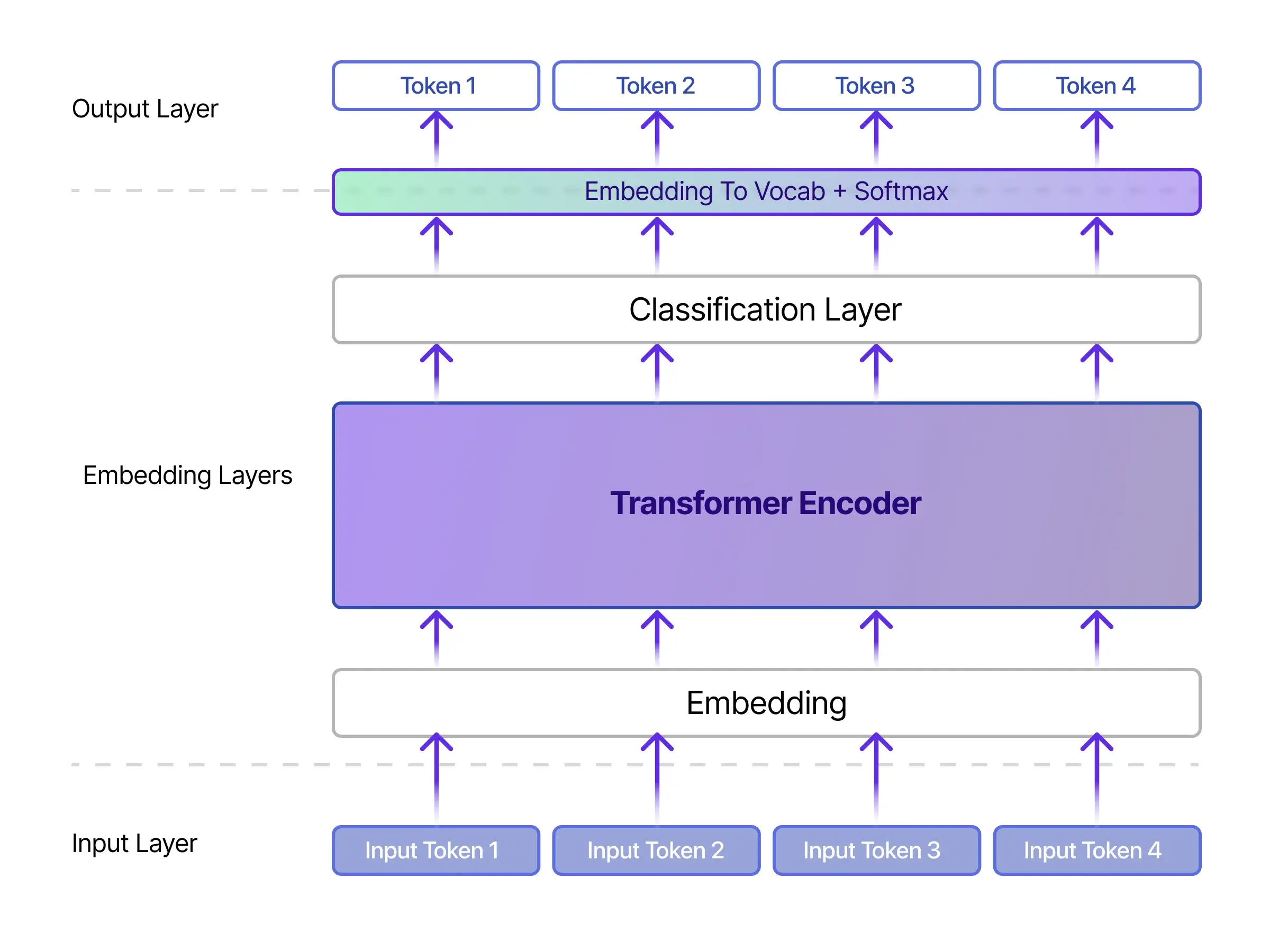
Image Courtesy: Markovate

Image Courtesy: Gitee
Here’s the journey of your text through a transformer model:
- Tokenization– Your text is broken into smaller units (words, subwords, or characters).
Example: “fix login issue” → [“fix”, “log”, “##in”, “issue”]
- Embedding Layer– Each token is converted into an initial numerical vector (a raw representation).
- Positional Encoding– Since word order matters (“dog bites man” ≠ “man bites dog”), transformers add positional information to keep track of sequence.
- Self-Attention Mechanism– This is the magic: the model looks at every word in relation to every other word to understand context.
Example: In “bank by the river,” the word “bank” gets more weight from “river” than from “loan.”
- Multi-Head Attention– The model repeats this “attention” process in parallel with multiple “heads,” each focusing on different aspects of meaning (e.g., syntax, relationships, topic).
- Feed-Forward Layers– The attention outputs are refined and passed through layers of non-linear transformations.
- Contextual Embeddings Output– Finally, the model produces embeddings that encode bothmeaning and context. These vectors are what power search, recommendations, and AI assistants.
In short: Transformers don’t just translate words into numbers — they understand relationshipsbetween words in context and create embeddings that machines can use to reason about meaning.
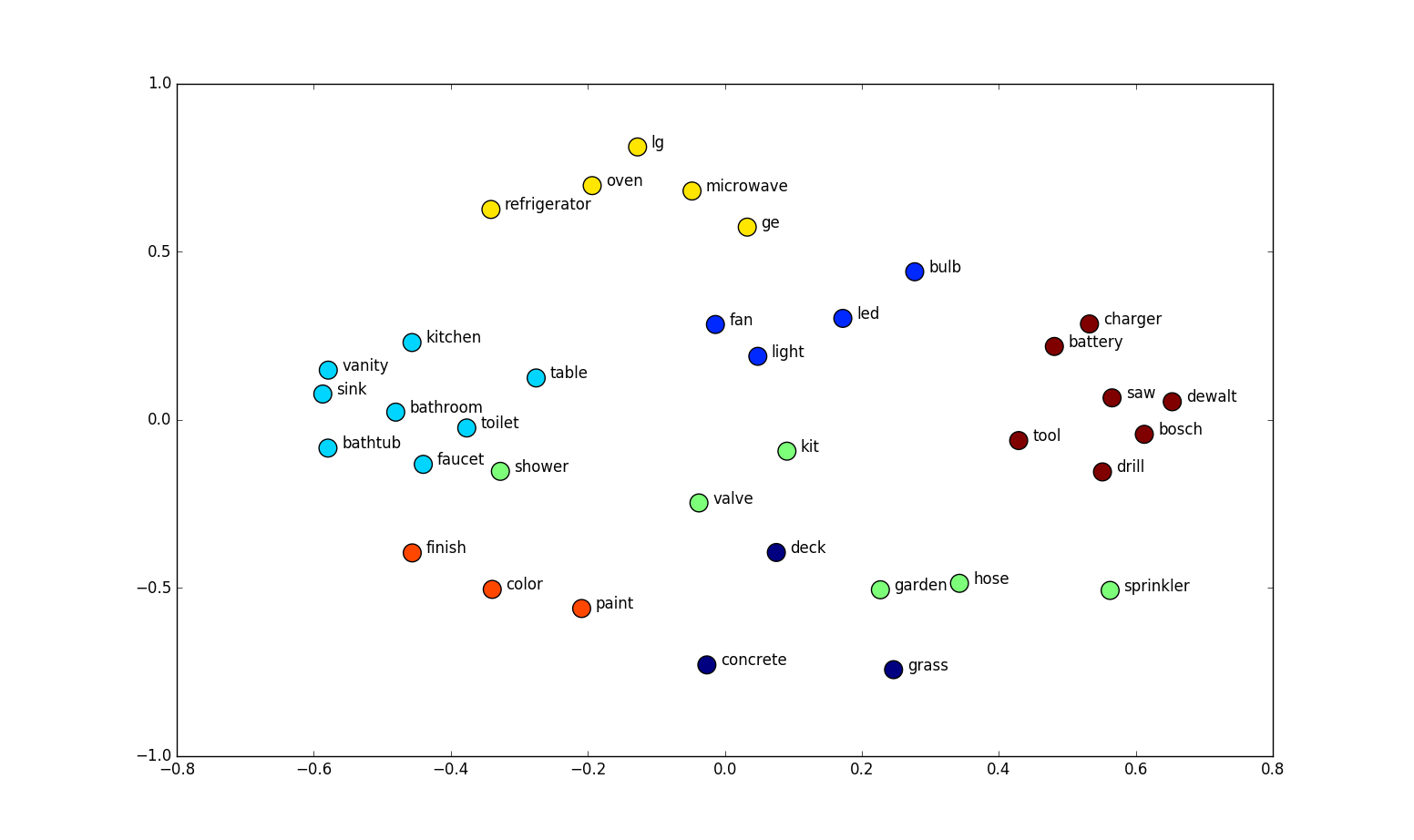
Image Courtesy: oregonstate
Real-World Use Cases of Semantic Embeddings
The applications of this technology span industries and use cases. Here are some of the most impactful ones:
- Semantic Search Engines
Traditional search engines match keywords. Semantic search engines match intent. When a user asks, “best places to eat Italian near me,” embeddings help understand it’s about restaurants, not Italian historyor language.
- AI Assistants & RAG (Retrieval-Augmented Generation)
Large language models (LLMs) like GPT are powerful, but without context, they can hallucinate. Embeddings enable AI assistants to retrieve the right documents and ground their answers in facts. That’s why RAG pipelines are now considered the gold standard for enterprise AI.
- Customer Insights & Analytics
Companies receive thousands of reviews, support tickets, and survey responses. Instead of manually tagging them, embeddings cluster them into themes like “delivery issues,” “pricing complaints,” or “feature requests.”
- Duplicate or Near-Duplicate Detection
Legal contracts, FAQs, or product descriptions often repeat information in slightly different wording. Embeddings make it easy to detect such semantic overlaps, saving hours of manual review.
- Personalized Recommendations
Think Netflix suggesting the next series or Spotify recommending a playlist. Embeddings map user preferences to content in a way that feels surprisingly accurate.
- Multimodal Search
With newer models, embeddings aren’t limited to text. They can also represent images, audio, or video. That means you can type “blue running shoes” and instantly see relevant images from a catalog.
These examples highlight one truth: semantic embeddings are no longer a research toy — they’re powering real-world, revenue-generating systems.
Why Everyone Loves Them
Here’s why semantic embeddings have gained so much traction:
- Context-Aware Understanding: Unlike older models, embeddings built with transformers recognize relationships and disambiguate meaning.
- High Accuracy: They achieve state-of-the-art performance in tasks like semantic similarity, clustering, and classification.
- Rich Ecosystem: Open-source libraries like Sentence-Transformersmake experimentation easy, while enterprise APIs from OpenAI, Google, and Cohereprovide production-grade solutions.
- Multilingual Support: Many embeddings are trained on dozens of languages, making global applications feasible.
- Versatility: From search to recommendations to analytics, embeddings are a general-purpose tool for meaning-based tasks.
The Challenges of Transformers for Semantic Embeddings
But like any powerful technology, semantic embeddings come with trade-offs:
- Cost & Infrastructure: Running large transformer models in production can be resource-intensive. Even inference (using pre-trained models) requires GPUs or managed cloud services.
- Need for Vector Databases: To make searches fast and scalable, embeddings must be paired with specialized storage systems like Milvus, FAISS, Pinecone, or Chroma. Traditional databases simply won’t cut it.
- Model Drift: Language evolves, and so does company-specific jargon. Without regular updates or fine-tuning, embeddings can become outdated.
- Interpretability: Vectors are not human-readable. Explaining whytwo pieces of text are considered similar can be challenging.Understanding these limitations helps organizations adopt embeddings wisely and plan for long-term sustainability.
Alternatives and Complements of Transformers for Semantic Embeddings
Not every problem needs embeddings. In some cases, simpler methods still work better:
- BM25 / TF-IDF: Great for keyword-heavy search where exact matches matter.
- Hybrid Search (Dense + Sparse): Combining embeddings with keyword search often gives the best results.
- Lightweight Models (MiniLM, DistilBERT): For smaller projects where compute and cost are constraints.
- Knowledge Graphs: Structured, relational queries are often easier with graph-based systems.
In practice, companies often use embeddings as part of a stack, not as a silver bullet.
Upcoming Trends and Industry Insightsof Transformers for Semantic Embeddings
The world of semantic embeddings is moving fast, and here are a few trends worth watching:
- Hybrid Retrieval Becomes Standard: More enterprises are blending sparse (keyword-based) and dense (embedding-based) methods for the best of both worlds.
- Multimodal Embeddings: Beyond text, embeddings are now connecting meaning across text, images, audio, and video. This opens doors to powerful cross-media search experiences.
- RAG Pipelines Everywhere: As enterprises adopt LLMs, retrieval-augmented generation (powered by embeddings) is becoming the default approach for safe, grounded answers.
- Cloud Democratization: Platforms like Google Vertex AI Searchand OpenAI Embeddings APIare lowering the barrier to entry. You don’t need a PhD in NLP anymore — just a few lines of code.
These trends make it clear: semantic embeddings are not a passing fad. They’re shaping the future of how humans and machines interact.
Project Referencesof Transformers of Semantic Embeddings
Frequently Asked Questions of Transformers for Semantic Embeddings
Q: Do I always need a vector database?
Not for small projects. For experiments or datasets under a few thousand documents, in-memory search is enough. But for millions of documents, vector databases are essential.
Q: Are embeddings limited to text?
No. Newer models generate embeddings for multimodal data — text, images, even audio and video.
Q: Which model should I start with?
For quick experiments, start with MiniLMor Sentence-BERT. For production, consider OpenAI embeddings APIor Google’s Vertex AI Search.
Q: How do embeddings fit with LLMs?
They’re complementary. Embeddings retrieve relevant information, while LLMs generate answers using that information. Together, they power reliable AI assistants.
Third Eye Data’s Take on Transformers for Semantic Embeddings
At ThirdEye Data, we treat transformer embeddings as a core pillarof our semantic AI solutions. We believe they unlock richer understanding of meaning and context, especially across domains and languages.
- We embed transformer models into production systems for search, indexing, and AI agents—not just experiments.
- We adopt hybrid architectures, combining embeddings with full-text search, metadata filtering, and fallback logic for robustness.
- We balance performance, cost, and precision, choosing lighter embeddings (FastText) when speed or resource constraints require, and deeper transformer embeddings when nuance and accuracy matter.
- We continuously evolve our methodologies—shifting legacy approaches (e.g. LDA or keyword matching) toward embedding-driven models when they yield stronger results.
In short: transformer embeddings are not a buzzword for us—they are a practical, high-value tool we deploy where they make sense, always accompanied by architectural safeguards and complementary techniques.
The rise of transformers for semantic embeddings marks a turning point in how we interact with information. They bridge the gap between human language and machine understanding, enabling applications that feel intelligent, personalized, and human-like.
Yes, they require careful planning — vector databases, regular updates, and thoughtful infrastructure. But the payoff is enormous: AI systems that don’t just process words, but understand meaning.
For businesses, this means smarter search, more accurate AI assistants, and insights hidden in plain sight within your data. For users, it means fewer frustrations and more moments of delight when technology “just gets it.”