Below is a high-level overview of Apache Flink and stream processing.
Before we go into detail about Flink, let’s review at a higher level the types of datasets you’re likely to encounter when processing data as well as types of execution models you can choose for processing. These two ideas are often conflated, and it’s useful to clearly separate them.
First, 2 types of datasets
Many real-world data sets that are traditionally thought of as bounded or “batch” data are in reality unbounded datasets. This is true whether the data is stored in a sequence of directories on HDFS or in a log-based system like Apache Kafka.
Examples of unbounded datasets include but are not limited to:
Second, 2 types of execution models
It’s possible, though not necessarily optimal, to process either type of dataset with either type of execution model. For instance, batch execution has long been applied to unbounded datasets despite potential problems with windowing, state management, and out-of-order data.
Flink relies on a streaming execution model, which is an intuitive fit for processing unbounded datasets: streaming execution is continuous processing on data that is continuously produced. And alignment between the type of dataset and the type of execution model offers many advantages with regard to accuracy and performance.
Flink is an open-source framework for distributed stream processing that:
Earlier, we discussed aligning the type of dataset (bounded vs. unbounded) with the type of execution model (batch vs. streaming). Many of the Flink features listed below–state management, handling of out-of-order data, flexible windowing–are essential for computing accurate results on unbounded datasets and are enabled by Flink’s streaming execution model.
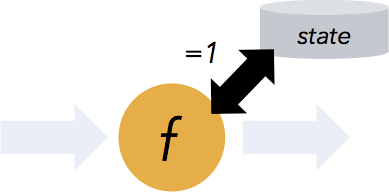

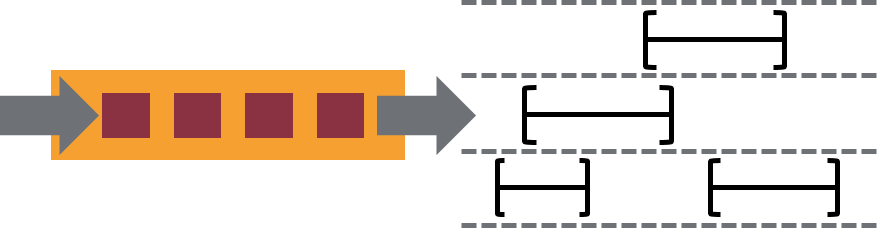
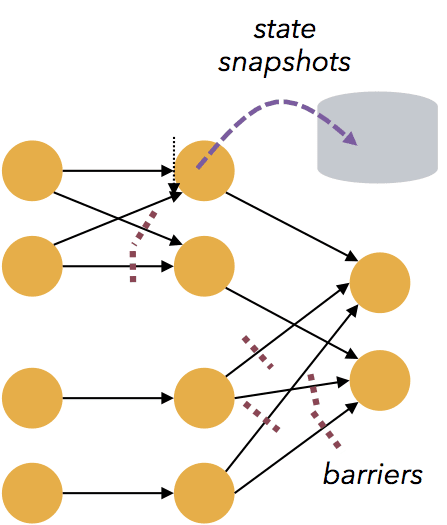
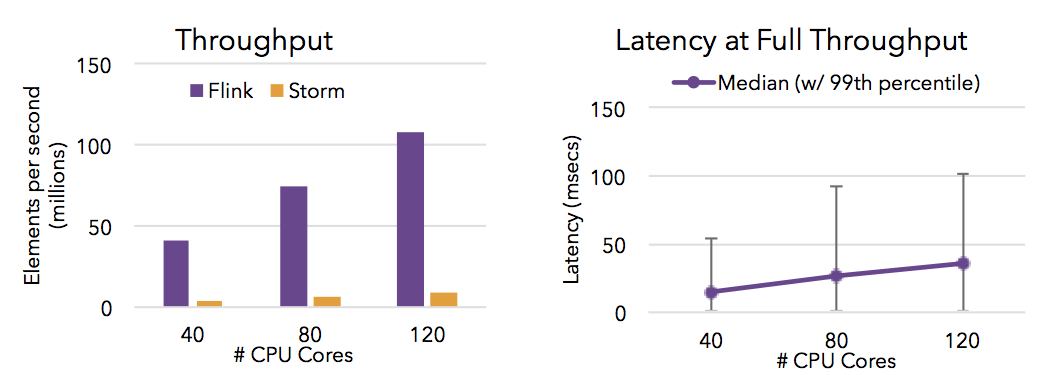
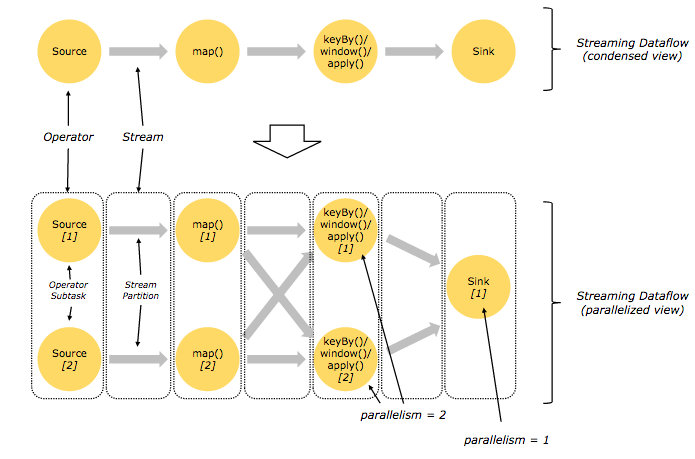
If you’ve reviewed Flink’s documentation, you might have noticed both a DataStream API for working with unbounded data as well as a DataSet API for working with bounded data.
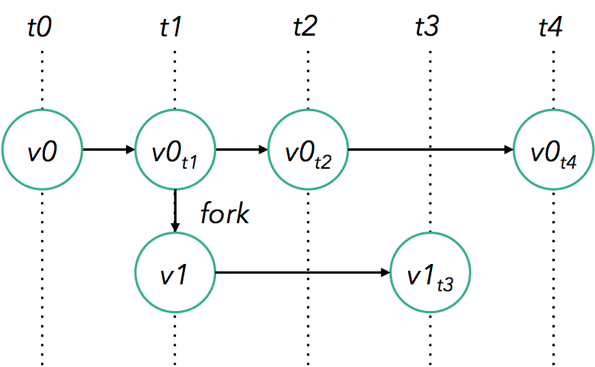
Earlier in this write-up, we introduced the streaming execution model (“processing that executes continuously, an event-at-a-time”) as an intuitive fit for unbounded datasets. So how do bounded datasets relate to the stream processing paradigm?
In Flink’s case, the relationship is quite natural. A bounded dataset can simply be treated as a special case of an unbounded one, so it’s possible to apply all of the same streaming concepts that we’ve laid out above to finite data.
This is exactly how Flink’s DataSet API behaves. A bounded dataset is handled inside of Flink as a “finite stream”, with only a few minor differences in how Flink manages bounded vs. unbounded datasets.
And so it’s possible to use Flink to process both bounded and unbounded data, with both APIs running on the same distributed streaming execution engine–a simple yet powerful architecture.
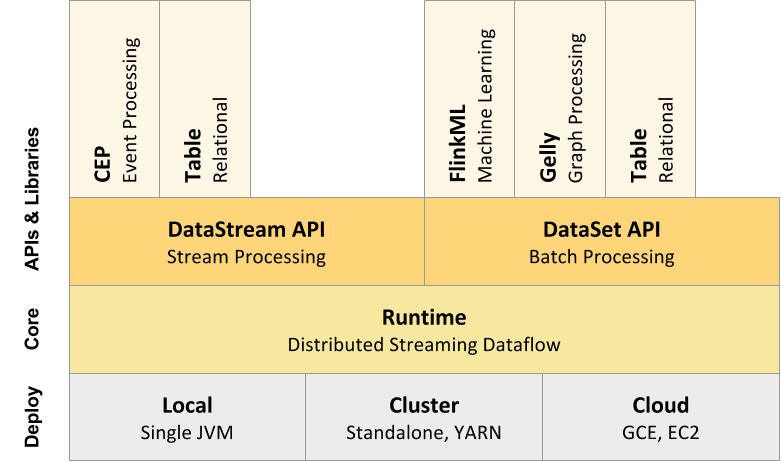
Flink can run in the cloud or on premise and on a standalone cluster or on a cluster managed by YARN or Mesos.
Flink’s core is a distributed streaming dataflow engine, meaning that data is processed an event-at-a-time rather than as a series of batches–an important distinction, as this is what enables many of Flink’s resilience and performance features that are detailed above.
Flink also includes special-purpose libraries for complex event processing, machine learning, graph processing, and Apache Storm compatibility.
At the most basic level, a Flink program is made up of:

A well-developed ecosystem is necessary for the efficient movement of data in and out of a Flink program, and Flink supports a wide range of connectors to third-party systems for data sources and sinks.
If you’re interested in learning more, we’ve collected information about the Flink ecosystem here.
In summary, Apache Flink is an open-source stream processing framework that eliminates the “performance vs. reliability” tradeoff often associated with open-source streaming engines and performs consistently in both categories. Following this introduction, we recommend you try our quickstart, download the most recent stable version of Flink, or review the documentation.
And we encourage you to join the Flink user mailing list and to share your questions with the community. We’re here to help you get the most out of Flink.

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

