Practical Transfer Learning Guide for Deep Learning Applications A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
Deep Learning on Steroids with the Power of Knowledge Transfer!
Introduction
Humans have an inherent ability to transfer knowledge across tasks. What we acquire as knowledge while learning about one task, we utilize in the same way to solve related tasks. The more related the tasks, the easier it is for us to transfer, or cross-utilize our knowledge. Some simple examples would be,
- Know how to ride a motorbike ⮫ Learn how to ride a car
- Know how to play classic piano ⮫ Learn how to play jazz piano
- Know math and statistics ⮫ Learn machine learning

In each of the above scenarios, we don’t learn everything from scratch when we attempt to learn new aspects or topics. We transfer and leverage our knowledge from what we have learnt in the past!
Conventional machine learning and deep learning algorithms, so far, have been traditionally designed to work in isolation. These algorithms are trained to solve specific tasks. The models have to be rebuilt from scratch once the feature-space distribution changes. Transfer learning is the idea of overcoming the isolated learning paradigm and utilizing knowledge acquired for one task to solve related ones. In this article, we will do a comprehensive coverage of the concepts, scope and real-world applications of transfer learning and even showcase some hands-on examples. To be more specific, we will be covering the following.
- Motivation for Transfer Learning
- Understanding Transfer Learning
- Transfer Learning Strategies
- Transfer Learning for Deep Learning
- Deep Transfer Learning Strategies
- Types of Deep Transfer Learning
- Applications of Transfer Learning
- Case Study 1: Image Classification with a Data Availability Constraint
- Case Study 2: Multi-Class Fine-grained Image Classification with Large Number of Classes and Less Data Availability
- Transfer Learning Advantages
- Transfer Learning Challenges
- Conclusion & Future Scope
We will look at transfer learning as a general high-level concept which started right from the days of machine learning and statistical modeling, however, we will be more focused around deep learning in this article.
Note: All the case studies will cover step by step details with code and outputs. The case studies depicted here and their results are purely based on actual experiments which we conducted when we implemented and tested these models while working on our book: Hands on Transfer Learning with Python (details at the end of this article).
This article aims to be an attempt to cover theoretical concepts as well as demonstrate practical hands-on examples of deep learning applications in one place, given the information overload which is out there on the web. All examples will be covered in Python using keras with a tensorflow backend, a perfect match for people who are veterans or just getting started with deep learning! Interested in PyTorch? Feel free to convert these examples and contact me and I’ll feature your work here and on GitHub!
Motivation for Transfer Learning
We have already briefly discussed that humans don’t learn everything from the ground up and leverage and transfer their knowledge from previously learnt domains to newer domains and tasks. Given the craze for True Artificial General Intelligence, transfer learning is something which data scientists and researchers believe can further our progress towards AGI. In fact, Andrew Ng, renowned professor and data scientist, who has been associated with Google Brain, Baidu, Stanford and Coursera, recently gave an amazing tutorial in NIPS 2016 called ‘Nuts and bolts of building AI applications using Deep Learning’ where he mentioned,
After supervised learning — Transfer Learning will be the next driver of ML commercial success
I recommend interested folks to check out his interesting tutorial from NIPS 2016.
In fact, transfer learning is not a concept which just cropped up in the 2010s. The Neural Information Processing Systems (NIPS) 1995 workshop Learning to Learn: Knowledge Consolidation and Transfer in Inductive Systems is believed to have provided the initial motivation for research in this field. Since then, terms such as Learning to Learn, Knowledge Consolidation, and Inductive Transfer have been used interchangeably with transfer learning. Invariably, different researchers and academic texts provide definitions from different contexts. In their famous book, Deep Learning, Goodfellow et al refer to transfer learning in the context of generalization. Their definition is as follows:
Situation where what has been learned in one setting is exploited to improve generalization in another setting.
Thus, the key motivation, especially considering the context of deep learning is the fact that most models which solve complex problems need a whole lot of data, and getting vast amounts of labeled data for supervised models can be really difficult, considering the time and effort it takes to label data points. A simple example would be the ImageNet dataset, which has millions of images pertaining to different categories, thanks to years of hard work starting at Stanford!

However, getting such a dataset for every domain is tough. Besides, most deep learning models are very specialized to a particular domain or even a specific task. While these might be state-of-the-art models, with really high accuracy and beating all benchmarks, it would be only on very specific datasets and end up suffering a significant loss in performance when used in a new task which might still be similar to the one it was trained on. This forms the motivation for transfer learning, which goes beyond specific tasks and domains, and tries to see how to leverage knowledge from pre-trained models and use it to solve new problems!
Understanding Transfer Learning
The first thing to remember here is that, transfer learning, is not a new concept which is very specific to deep learning. There is a stark difference between the traditional approach of building and training machine learning models, and using a methodology following transfer learning principles.
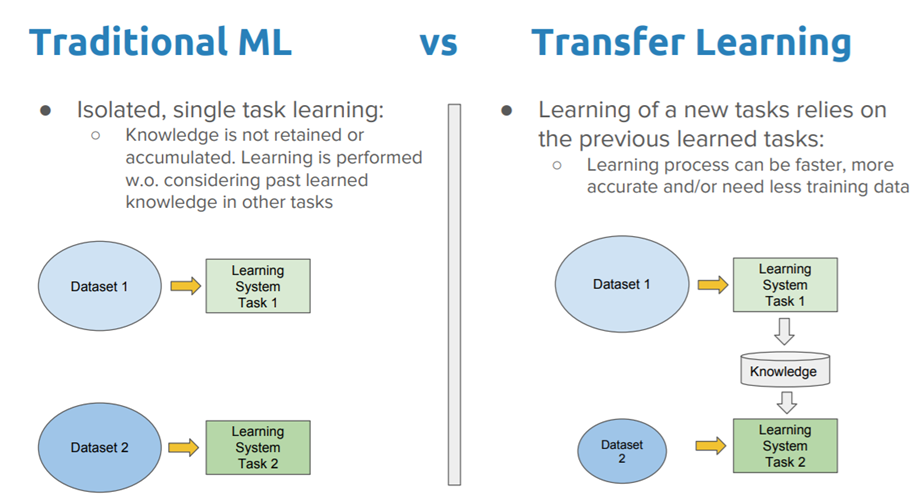
Traditional learning is isolated and occurs purely based on specific tasks, datasets and training separate isolated models on them. No knowledge is retained which can be transferred from one model to another. In transfer learning, you can leverage knowledge (features, weights etc) from previously trained models for training newer models and even tackle problems like having less data for the newer task!
Let’s understand the preceding explanation with the help of an example. Let’s assume our task is to identify objects in images within a restricted domain of a restaurant. Let’s mark this task in its defined scope as T1. Given the dataset for this task, we train a model and tune it to perform well (generalize) on unseen data points from the same domain (restaurant). Traditional supervised ML algorithms break down when we do not have sufficient training examples for the required tasks in given domains. Suppose, we now must detect objects from images in a park or a café (say, task T2). Ideally, we should be able to apply the model trained for T1, but in reality, we face performance degradation and models that do not generalize well. This happens for a variety of reasons, which we can liberally and collectively term as the model’s bias towards training data and domain.
Transfer learning should enable us to utilize knowledge from previously learned tasks and apply them to newer, related ones. If we have significantly more data for task T1, we may utilize its learning, and generalize this knowledge (features, weights) for task T2 (which has significantly less data). In the case of problems in the computer vision domain, certain low-level features, such as edges, shapes, corners and intensity, can be shared across tasks, and thus enable knowledge transfer among tasks! Also, as we have depicted in the earlier figure, knowledge from an existing task acts as an additional input when learning a new target task.
Source: A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning