HOW STORM WORKS
A storm cluster has three sets of nodes:
- Nimbus node (master node, similar to the Hadoop JobTracker):
- Uploads computations for execution
- Distributes code across the cluster
- Launches workers across the cluster
- Monitors computation and reallocates workers as needed
- ZooKeeper nodes – coordinates the Storm cluster
- Supervisor nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus

Five key abstractions help to understand how Storm processes data:
- Tuples– an ordered list of elements. For example, a “4-tuple” might be (7, 1, 3, 7)
- Streams – an unbounded sequence of tuples.
- Spouts –sources of streams in a computation (e.g. a Twitter API)
- Bolts – process input streams and produce output streams. They can: run functions; filter, aggregate, or join data; or talk to databases.
- Topologies – the overall calculation, represented visually as a network of spouts and bolts (as in the following diagram)
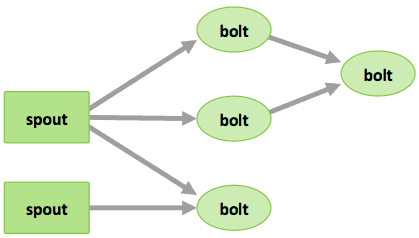
Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed into Hadoop.
Learn more about how the community is working to integrate Storm with Hadoop and improve its readiness for the enterprise







