What is AWS Data Pipeline?
AWS Data Pipeline is a web service that you can use to automate the movement and transformation of data. With AWS Data Pipeline, you can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. You define the parameters of your data transformations and AWS Data Pipeline enforces the logic that you’ve set up.
The following components of AWS Data Pipeline work together to manage your data:
- A pipeline definition specifies the business logic of your data management. For more information, see Pipeline Definition File Syntax.
- A pipeline schedules and runs tasks. You upload your pipeline definition to the pipeline and then activate the pipeline. You can edit the pipeline definition for a running pipeline and activate the pipeline again for it to take effect. You can deactivate the pipeline, modify a data source, and then activate the pipeline again. When you are finished with your pipeline, you can delete it.
- Task Runner polls for tasks and then performs those tasks. For example, Task Runner could copy log files to Amazon S3 and launch Amazon EMR clusters. Task Runner is installed and runs automatically on resources created by your pipeline definitions. You can write a custom task runner application, or you can use the Task Runner application that is provided by AWS Data Pipeline. For more information, see Task Runners.
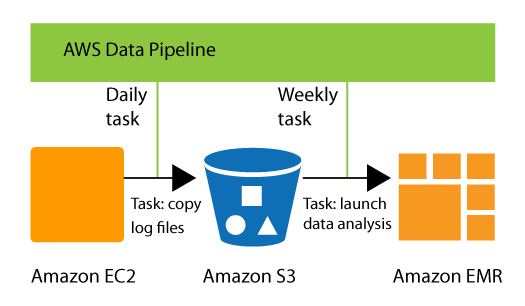
For example, you can use AWS Data Pipeline to archive your web server’s logs to Amazon Simple Storage Service (Amazon S3) each day and then run a weekly Amazon EMR (Amazon EMR) cluster over those logs to generate traffic reports. AWS Data Pipeline schedules the daily tasks to copy data and the weekly task to launch the Amazon EMR cluster. AWS Data Pipeline also ensures that Amazon EMR waits for the final day’s data to be uploaded to Amazon S3 before it begins its analysis, even if there is an unforeseen delay in uploading the logs.
AWS Data Pipeline works with the following services to store data.
AWS Data Pipeline works with the following compute services to transform data.
- Amazon EC2 — Provides resizeable computing capacity—literally, servers in Amazon’s data centers—that you use to build and host your software systems. For more information, see Amazon EC2 User Guide for Linux Instances.
- Amazon EMR — Makes it easy, fast, and cost-effective for you to distribute and process vast amounts of data across Amazon EC2 servers, using a framework such as Apache Hadoop or Apache Spark. For more information, see Amazon EMR Developer Guide.
Accessing AWS Data Pipeline
You can create, access, and manage your pipelines using any of the following interfaces:
- AWS Management Console— Provides a web interface that you can use to access AWS Data Pipeline.
- AWS Command Line Interface (AWS CLI) — Provides commands for a broad set of AWS services, including AWS Data Pipeline, and is supported on Windows, Mac, and Linux. For more information about installing the AWS CLI, see AWS Command Line Interface. For a list of commands for AWS Data Pipeline, see data pipeline.
- AWS SDKs — Provides language-specific APIs and takes care of many of the connection details, such as calculating signatures, handling request retries, and error handling. For more information, see AWS SDKs.
- Query API— Provides low-level APIs that you call using HTTPS requests. Using the Query API is the most direct way to access AWS Data Pipeline, but it requires that your application handle low-level details such as generating the hash to sign the request, nd error handling. For more information, see the AWS Data Pipeline API Reference.
Pricing
With Amazon Web Services, you pay only for what you use. For AWS Data Pipeline, you pay for your pipeline based on how often your activities and preconditions are scheduled to run and where they run. For pricing information, see AWS Data Pipeline Pricing
If your AWS account is less than 12 months old, you are eligible to use the free tier. The free tier includes 3 low-frequency preconditions and 5 low-frequency activities per month at no charge. For more information, see AWS Free Tier.
AWS Data Pipeline: Defining and Automating Your Data Workflows
A pipeline definition is how you communicate your business logic to AWS Data Pipeline. It contains the following information:
- Names, locations, and formats of your data sources
- Activities that transform the data
- The schedule for those activities
- Resources that run your activities and preconditions
- Preconditions that must be satisfied before the activities can be scheduled
- Ways to alert you with status updates as pipeline execution proceeds
From your pipeline definition, AWS Data Pipeline determines the tasks, schedules them, and assigns them to task runners. If a task is not completed successfully, AWS Data Pipeline retries the task according to your instructions and, if necessary, reassigns it to another task runner. If the task fails repeatedly, you can configure the pipeline to notify you.
For example, in your pipeline definition, you might specify that log files generated by your application are archived each month in 2013 to an Amazon S3 bucket. AWS Data Pipeline would then create 12 tasks, each copying over a month’s worth of data, regardless of whether the month contained 30, 31, 28, or 29 days.
You can create a pipeline definition in the following ways:
- Graphically, by using the AWS Data Pipeline console
- Textually, by writing a JSON file in the format used by the command line interface
- Programmatically, by calling the web service with either one of the AWS SDKs or the AWS Data Pipeline API
A pipeline definition can contain the following types of components.
Pipeline Components
- Data Nodes
- The location of input data for a task or the location where output data is to be stored.
- Activities
- A definition of work to perform on a schedule using a computational resource and typically input and output data nodes.
- Preconditions
- A conditional statement that must be true before an action can run.
- Scheduling Pipelines
- Defines the timing of a scheduled event, such as when an activity runs.
- Resources
- The computational resource that performs the work that a pipeline defines.
- Actions
- An action that is triggered when specified conditions are met, such as the failure of an activity.
For more information, see Pipeline Definition File Syntax.
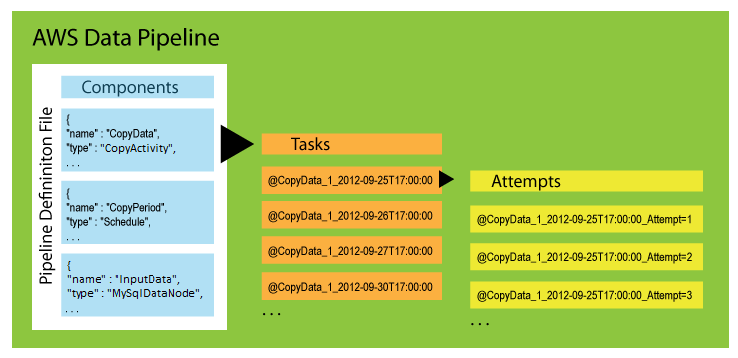
Pipeline Components, Instances, and Attempts
There are three types of items associated with a scheduled pipeline:
- Pipeline Components — Pipeline components represent the business logic of the pipeline and are represented by the different sections of a pipeline definition. Pipeline components specify the data sources, activities, schedule, and preconditions of the workflow. They can inherit properties from parent components. Relationships among components are defined by reference. Pipeline components define the rules of data management; they are not a to-do list.
- Instances — When AWS Data Pipeline runs a pipeline, it compiles the pipeline components to create a set of actionable instances. Each instance contains all the information for performing a specific task. The complete set of instances is the to-do list of the pipeline. AWS Data Pipeline hands the instances out to task runners to process.
- Attempts — To provide robust data management, AWS Data Pipeline retries a failed operation. It continues to do so until the task reaches the maximum number of allowed retry attempts. Attempt objects track the various attempts, results, and failure reasons if applicable. Essentially, it is the instance with a counter. AWS Data Pipeline performs retries using the same resources from the previous attempts, such as Amazon EMR clusters and EC2 instances.
Note
Retrying failed tasks is an important part of a fault tolerance strategy, and AWS Data Pipeline pipeline definitions provide conditions and thresholds to control retries. However, too many retries can delay detection of an unrecoverable failure because AWS Data Pipeline does not report failure until it has exhausted all the retries that you specify. The extra retries may accrue additional charges if they are running on AWS resources. As a result, carefully consider when it is appropriate to exceed the AWS Data Pipeline default settings that you use to control re-tries and related settings.
Source: What is AWS Data Pipeline? – AWS Data Pipeline