Simple, scalable and serverless data integration
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months.
Data integration is the process of preparing and combining data for analytics, machine learning, and application development. It involves multiple tasks, such as discovering and extracting data from various sources; enriching, cleaning, normalizing, and combining data; and loading and organizing data in databases, data warehouses, and data lakes. These tasks are often handled by different types of users that each use different products.
AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data using the AWS Glue Data Catalog. Data engineers and ETL (extract, transform, and load) developers can visually create, run, and monitor ETL workflows with a few clicks in AWS Glue Studio. Data analysts and data scientists can use AWS Glue DataBrewto visually enrich, clean, and normalize data without writing code. With AWS Glue Elastic Views, application developers can use familiar Structured Query Language (SQL) to combine and replicate data across different data stores.
Benefits
Different groups across your organization can use AWS Glue to work together on data integration tasks, including extraction, cleaning, normalization, combining, loading, and running scalable ETL workflows. This way, you reduce the time it takes to analyze your data and put it to use from months to minutes.
AWS Glue runs in a serverless environment. There is no infrastructure to manage, and AWS Glue provisions, configures, and scales the resources required to run your data integration jobs. You pay only for the resources your jobs use while running.
AWS Glue automates much of the effort required for data integration. AWS Glue crawls your data sources, identifies data formats, and suggests schemas to store your data. It automatically generates the code to run your data transformations and loading processes. You can use AWS Glue to easily run and manage thousands of ETL jobs or to combine and replicate data across multiple data stores using SQL.
AWS Glue can run your ETL jobs as new data arrives. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
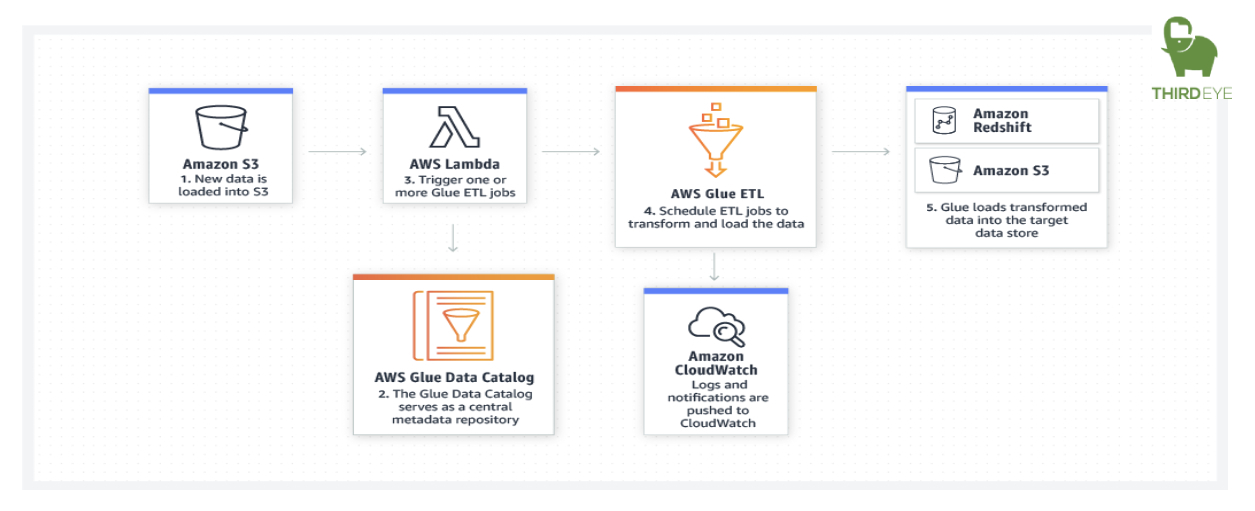
You can use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
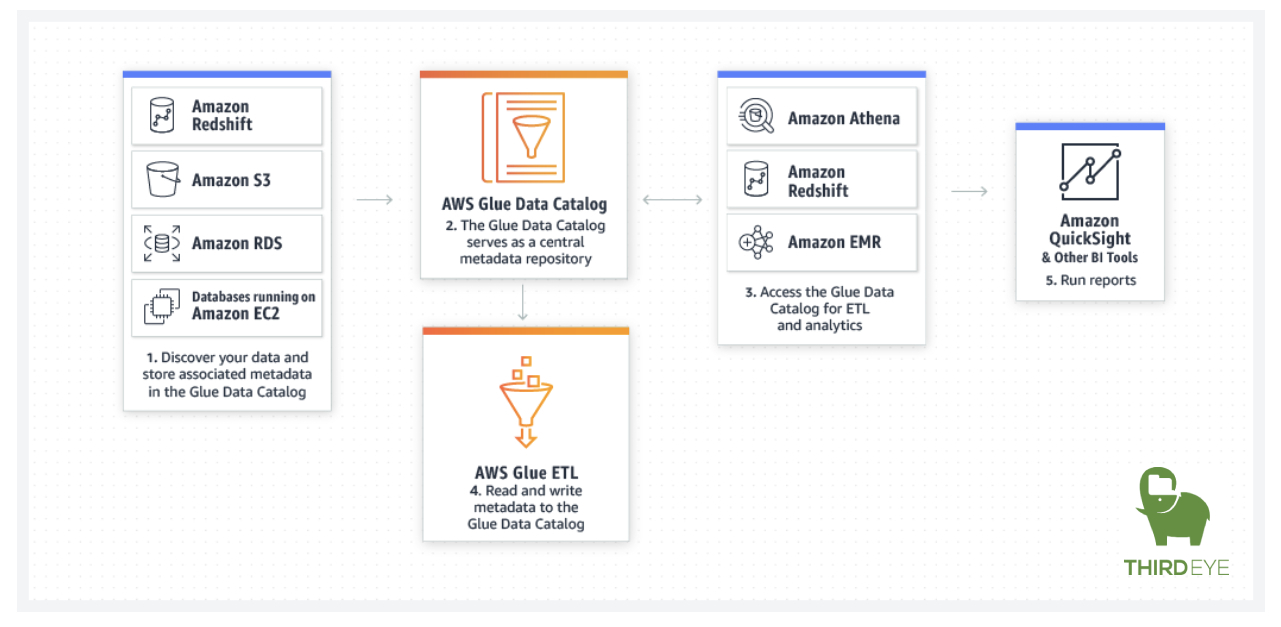
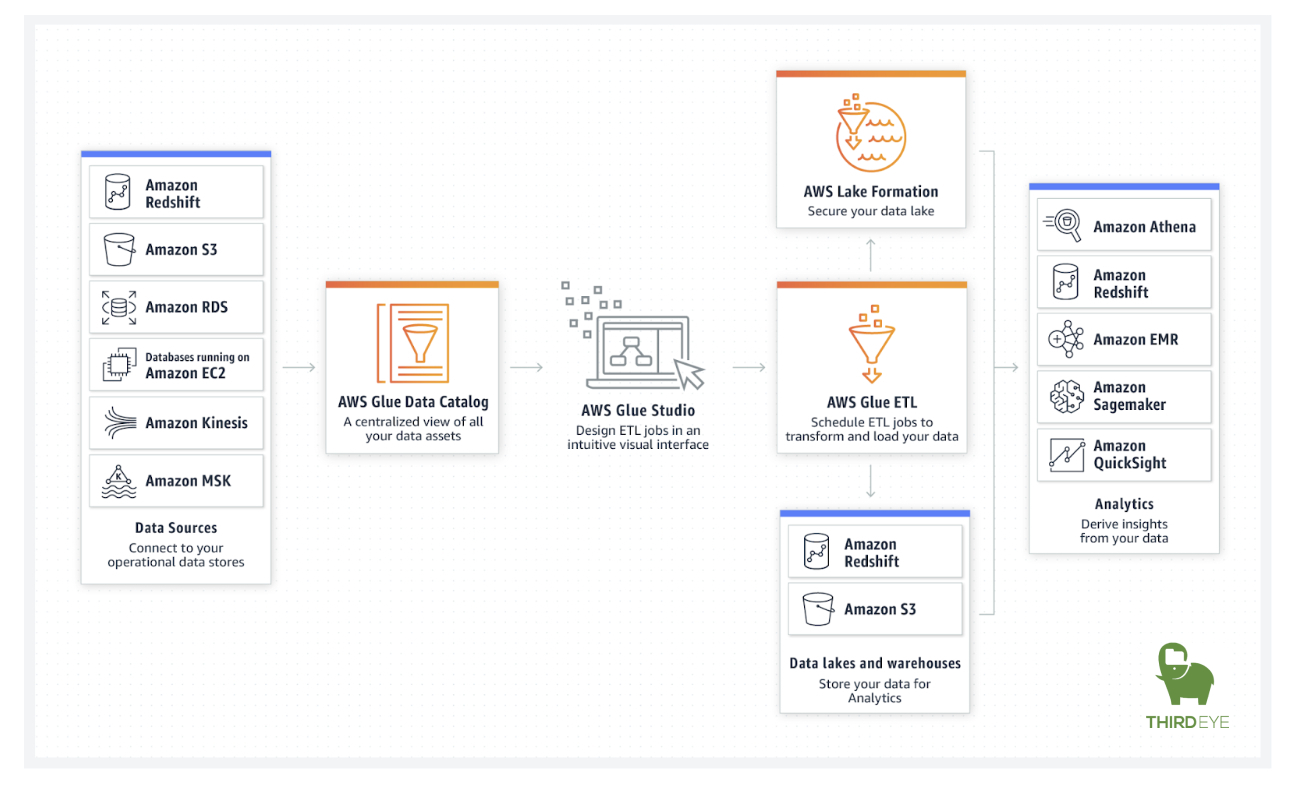
AWS Glue Studio makes it easy to visually create, run, and monitor AWS Glue ETL jobs. You can compose ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code. You can then use the AWS Glue Studio job run dashboard to monitor ETL execution and ensure that your jobs are operating as intended.
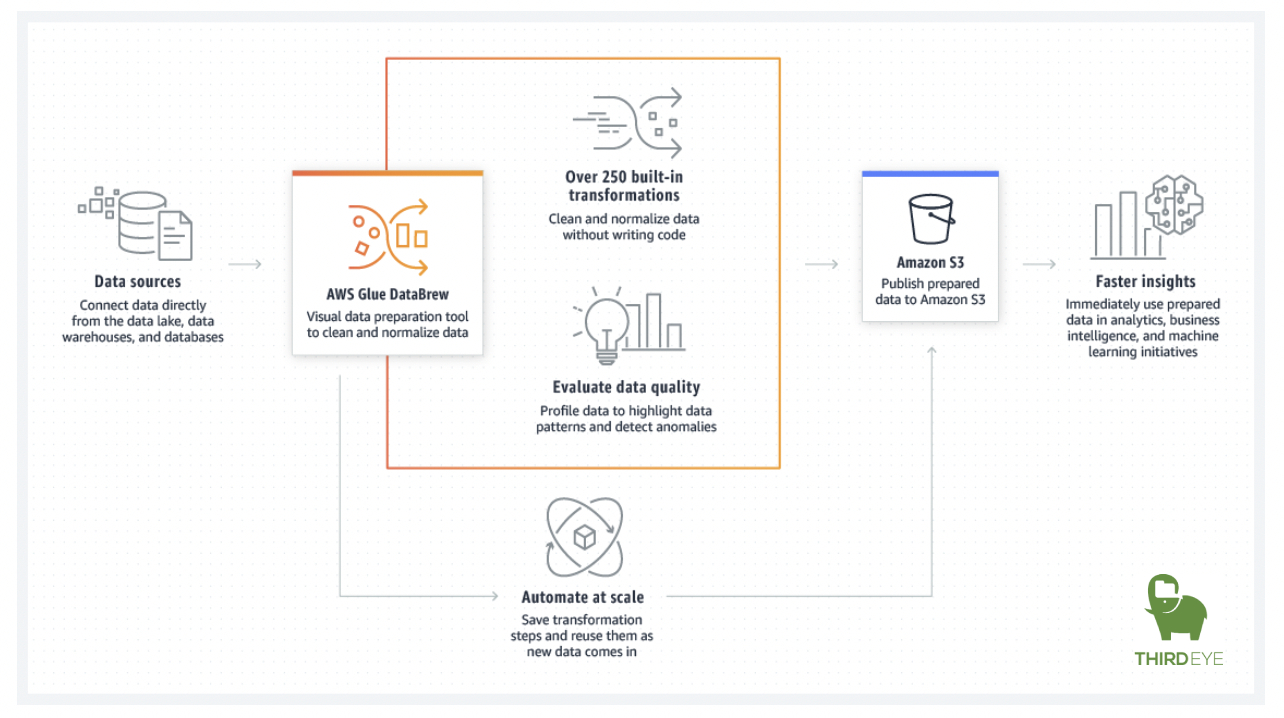
AWS Glue DataBrew enables you to explore and experiment with data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon RDS. You can choose from over 250 prebuilt transformations in AWS Glue DataBrew to automate data preparation tasks, such as filtering anomalies, standardizing formats, and correcting invalid values. After the data is prepared, you can immediately use it for analytics and machine learning. Learn more about AWS Glue DataBrew here.
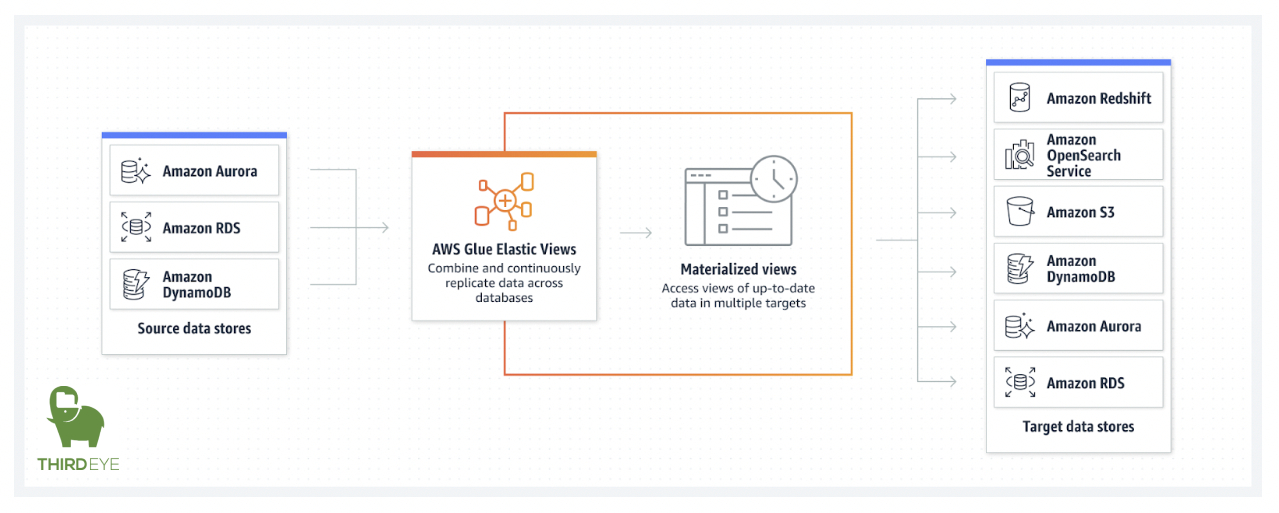
AWS Glue Elastic Views enables you to use familiar SQL to create materialized views. Use these views to access and combine data from multiple source data stores, and keep that combined data up-to-date and accessible from a target data store. The AWS Glue Elastic Views preview currently supports Amazon DynamoDB as a source, with support for Amazon Aurora and Amazon RDS to follow. Currently supported targets are Amazon Redshift, Amazon S3, and Amazon OpenSearch Service, with support for Amazon Aurora, Amazon RDS, and Amazon DynamoDB to follow. Learn more about AWS Glue Elastic Views here.
Information Sourced From – AWS Amazon





