Couchbase is the merge of two popular NoSQL technologies:
Like other NoSQL technologies, both Membase and CouchDB are built from the ground up on a highly distributed architecture, with data shared across machines in a cluster. Built around the Memcached protocol, Membase provides an easy migration to existing Memcached users who want to add persistence, sharding and fault resilience on their familiar Memcached model. On the other hand, CouchDB provides first class support for storing JSON documents as well as a simple RESTful API to access them. Underneath, CouchDB also has a highly tuned storage engine that is optimized for both update transaction as well as query processing. Taking the best of both technologies, Membase is well-positioned in the NoSQL marketplace.
Couchbase provides client libraries for different programming languages such as Java / .NET / PHP / Ruby / C / Python / Node.js
For read, Couchbase provides a key-based lookup mechanism where the client is expected to provide the key, and only the server hosting the data (with that key) will be contacted.
Couchbase also provides a query mechanism to retrieve data where the client provides a query (for example, range based on some secondary key) as well as the view (basically the index). The query will be broadcasted to all servers in the cluster and the result will be merged and sent back to the client.
For write, Couchbase provides a key-based update mechanism where the client sends an updated document with the key (as doc id). When handling writes request, the server will return to client’s write request as soon as the data is stored in RAM on the active server, which offers the lowest latency for write requests.
Following is the core API that Couchbase offers. (in an abstract sense)
# Get a document by key doc = get(key) # Modify a document, notice the whole document # need to be passed in set(key, doc) # Modify a document when no one has modified it # since my last read casVersion = doc.getCas() cas(key, casVersion, changedDoc) # Create a new document, with an expiration time # after which the document will be deleted addIfNotExist(key, doc, timeToLive) # Delete a document delete(key) # When the value is an integer, increment the integer increment(key) # When the value is an integer, decrement the integer decrement(key) # When the value is an opaque byte array, append more # data into existing value append(key, newData) # Query the data results = query(viewName, queryParameters) In Couchbase, document is the unit of manipulation. Currently Couchbase doesn't support server-side execution of custom logic.Couchbase server is basically a passive store and unlike other document oriented DB, Couchbase doesn't support field-level modification. In case of modifying documents, client need to retrieve documents by its key, do the modification locally and then send back the whole (modified) document back to the server. Couchbase currently doesn't support bulk modification based on a condition matching. Modification happens only in a per document basis. (client will save the modified document one at a time).
Similar to many NOSQL databases, Couchbase’s transaction model is primitive as compared to RDBMS. Atomicity is guaranteed at a single document and transactions that span update of multiple documents are unsupported.To provide necessary isolation for concurrent access, Couchbase provides a CAS (compare and swap) mechanism which works as follows …
In a typical setting, a Couchbase DB resides in a server cluster involving multiple machines. The client library will connect to the appropriate servers to access the data. Each machine contains a number of daemon processes which provides data access as well as management functions.
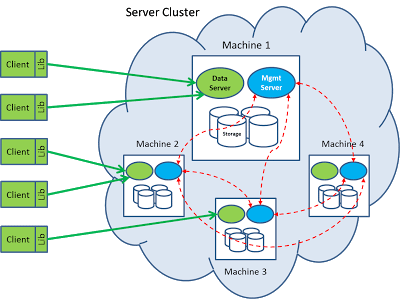
The data server, written in C/C++, is responsible to handle get/set/delete request from the client. The Management server, written in Erlang, is responsible to handle the query traffic from the client, as well as manage the configuration and communicate with other member nodes in the cluster.
The basic unit of data storage in Couchbase DB is a JSON document (or primitive data type such as int and byte array) which is associated with a key. The overall key space is partitioned into 1024 logical storage unit called “virtual buckets” (or vBucket). vBucket is distributed across machines within the cluster via a map that is shared among servers in the cluster as well as the client library.
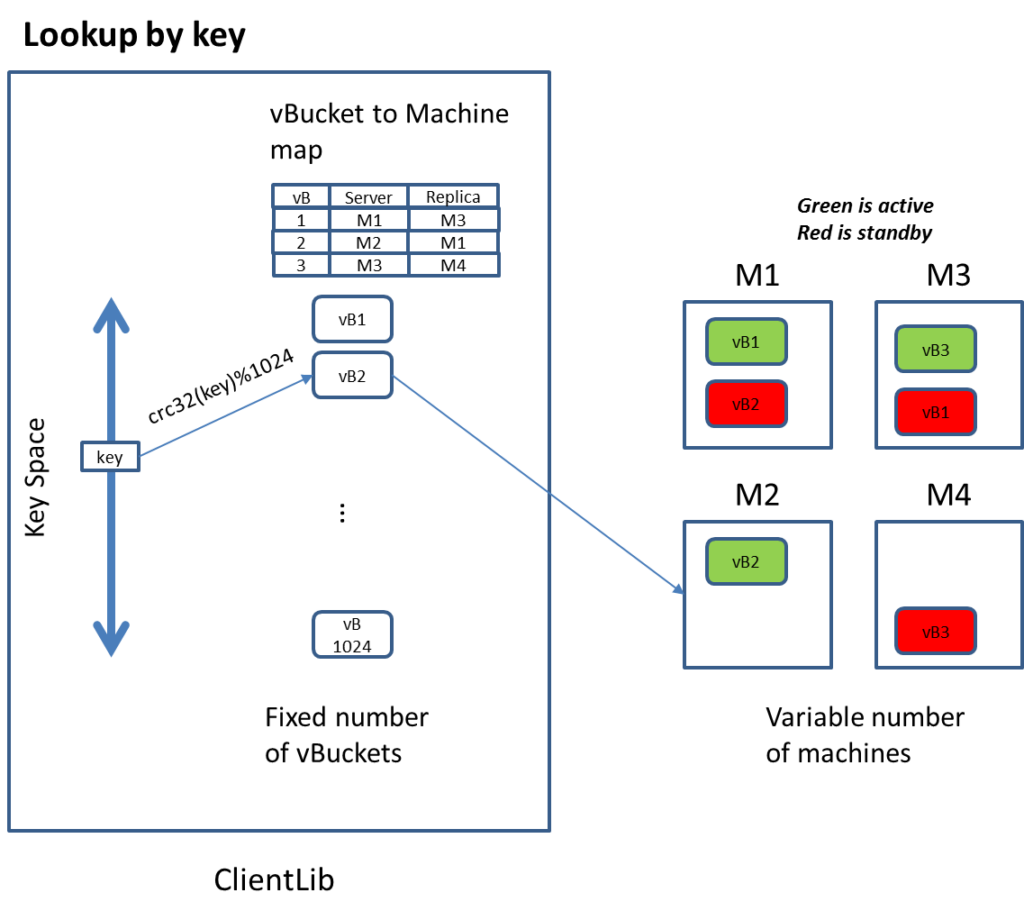
High availability is achieved through data replication at the vBucket level. Currently, Couchbase supports one active vBucket zero or more standby replicas hosted on other machines. Currently, the standby server is idle and not serving any client request. In the future version of Couchbase, the standby replica will be able to serve read request.
Load balancing in Couchbase is achieved as follows:
Management server performs the management function and co-ordinates the other nodes within the cluster. It includes the following monitoring and administration functions
Heartbeat: A watchdog process periodically communicates with all member nodes within the same cluster to provide Couchbase Server health updates.
Process monitor: This subsystem monitors the execution of the local data manager, restarting failed processes as required and provide status information to the heartbeat module.
Configuration manager: Each Couchbase Server node shares a cluster-wide configuration which contains the member nodes within the cluster, a vBucket map. The configuration manager pulls this config from other member nodes at bootup time.
Within a cluster, one node’s Management Server will be elected as the leader which performs the following cluster-wide management function
If the leader node crashes, a new leader will be elected from surviving members in the cluster.
When a machine in the cluster has crashed, the leader will detect that and notify member machines in the cluster that all vBuckets hosted in the crashed machine are dead. After getting this signal, machines hosting the corresponding vBucket replica will set the vBucket status as “active”. The vBucket/server map is updated and eventually propagated to the client lib. Notice that at this moment, the replication level of the vBucket will be reduced. Couchbase doesn’t automatically re-create new replicas which will cause data copying traffic. An administrator can issue a command to explicitly initiate a data rebalancing. The crashed machine after reboot can rejoin the cluster. At this moment, all the data it stores previously will be completely discarded and the machine will be treated as a brand new empty machine.
As more machines are put into the cluster (for scaling out), vBucket should be redistributed to achieve a load balance. This is currently triggered by an explicit command from the administrator. Once receive the “rebalance” command, the leader will compute the new provisional map which has the balanced distribution of vBuckets and sends this provisional map to all members of the cluster.
To compute the vBucket map and migration plan, the leader attempts the following objectives:
Once the vBucket maps are determined, the leader will pass the redistribution map to each member in the cluster and coordinate the steps of vBucket migration. The actual data transfer happens directly between the origination node to the destination node.
Notice that since we have generally more vBuckets than machines. The workload of migration will be evenly distributed automatically. For example, when new machines are added into the clusters, all existing machines will migrate some portion of its vBucket to the new machines. There is no single bottleneck in the cluster.
Throughput the migration and redistribution of vBucket among servers, the life cycle of a vBucket in a server will be in one of the following states
Data server implements the Memcached APIs such as get, set, delete, append, prepend, etc. It contains the following key data structure:
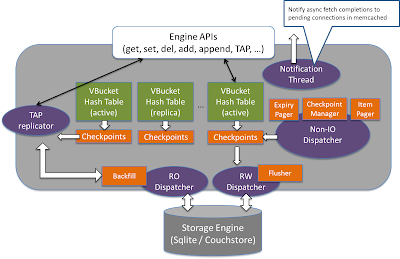
To handle a “GET” request
To handle a “SET” request, a success response will be returned to the calling client once the updated document has been put into the in-memory hash table with a write request put into the checkpoint buffer. Later on, the Flusher thread will pick up the outstanding write request from each checkpoint buffer, lookup the corresponding document content from the hashtable and write it out to the storage engine.
Of course, data can be lost if the server crashes before the data has been replicated to another server and/or persisted. If the client requires a high data availability across different crashes, it can issue a subsequent observe() call which blocks on the condition that the server persists data on disk, or the server has replicated the data to another server (and get its ACK). Overall speaking, the client has various options to tradeoff data integrity with throughput.
Hashtable Management To synchronize accesses to a vbucket hash table, each incoming thread needs to acquire a lock before accessing a key region of the hash table. There are multiple locks per vbucket hash table, each of which is responsible for controlling exclusive accesses to a certain ket region on that hash table. The number of regions of a hash table can grow dynamically as more documents are inserted into the hash table.
To control the memory size of the hashtable, Item pager thread will monitor the memory utilization of the hashtable. Once a high watermark is reached, it will initiate an eviction process to remove certain document content from the hashtable. Only entries that are not referenced by entries in the checkpoint buffer can be evicted because otherwise the outstanding update (which only exists in hashtable but not persisted) will be lost.
After the eviction, the entry of the document still remains in the hash table; only the document content of the document will be removed from memory but the metadata is still there. The eviction process stops after reaching the low watermark. The high/low water mark is determined by the bucket memory quota. By default, the high water mark is set to 75% of bucket quota, while the low water mark is set to 60% of bucket quota. These watermarks can be configurable at runtime.
In CouchDB, every document is associated with an expiration time and will be deleted once it is expired. Expiry pager is responsible for tracking and removing the expired document from both the hashtable as well as the storage engine (by scheduling a delete operation).
Checkpoint Manager
Checkpoint manager is responsible to recycle the checkpoint buffer, which holds the outstanding update request, consumed by the two downstream processes, Flusher, and TAP replicator. When all the request in the checkpoint buffer has been processed, the checkpoint buffer will be deleted and a new one will be created.
TAP Replicator
TAP replicator is responsible to handle vBucket migration as well as vBucket replication from active server to replica server. It does this by propagating the latest modified document to the corresponding replica server.
At the time a replica vBucket is established, the entire vBucket need to be copied from the active server to the empty destination replica server as follows
After the replica server has caught up, subsequent update at the active server will be available at its checkpoint buffer which will be pickup by the TAP replicator and send to the replica server.
Source: Everything You Need To Know About Couchbase Architecture – DZone Database

Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

