ETL Pipeline Demonstration Using Apache NiFi
Introduction:
Apache NiFi is an integrated data logistics platform for automating the movement of data between disparate systems. It provides real-time control that makes it easy to manage the movement of data between any source and any destination. It is data source agnostic, supporting disparate and distributed sources of differing formats, schemas, protocols, speeds, and sizes such as machines, geolocation devices, click streams, files, social feeds, log files and videos and more. It is configurable plumbing for moving data around, similar to how FedEx, UPS or other courier delivery services move parcels around. And just like those services, Apache NiFi allows you to trace your data in real-time, just like you could trace a delivery.
Apache NiFi is based on technology previously called “Niagara Files” that was in development and used at scale within the NSA for the last eight years and was made available to the Apache Software Foundation through the NSA Technology Transfer Program. As such, it was designed from the beginning to be a field ready—flexible, extensible and suitable for a wide range of devices from a small lightweight network edge device such as a Raspberry Pi to enterprise data clusters and the cloud. Apache NiFi is also able to dynamically adjust to fluctuating network connectivity that could impact communications and thus the delivery of data.
Prerequisites:
To follow this tutorial, you will need:
- JAVA and set the JAVA_HOME to .bashrc file
Installation of Apache NiFi:
- NiFi can be downloaded from the NiFi Downloads Page.
- Decompress and untar into the desired installation directory.
- Navigate to the NiFi installation directory.
- Then run the command: $ sudo bin/nifi.sh start
- By following the command you can track Apache NiFi is started or not:
$ sudo bin/nifi.sh status
- For example, we have downloaded the Apache NiFi and uncompressed under the Apache directory; please follow the below snapshot.
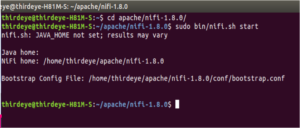
Fig: Getting Started with Apache NiFi
- After started the Apache NiFi, Go to a web browser and hit http://localhost:8080/nifi/
- By default, Apache NiFi uses 8080 port but you can change the port number from configuration file i.e. nifi.properties which is located under conf directory. Name of the property is nifi.web.http.port. In our case, we have changed from 8080 to 9000.
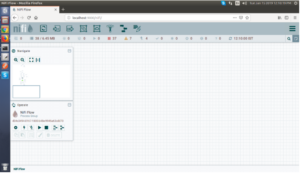
Fig: Apache NiFi Dashboard
Problem Statement:
- Download a zip file from an HTTP server and save it into a local machine.
- Then uncompress the downloaded zip file (note: downloaded zip file contains 3 csv file) and after that take a csv file and then clean the csv file because that csv file contains few junk values.
- Then send that csv file through flowfile and dump the all values into MySQL.
- Then extract the all data which is stored in MySQL into a csv file.
- After that, upload the csv file in an Amazon S3 bucket and HDFS.
- After successfully saving the file into desired locations it will send a confirmation mail to a specified user.
Overview:
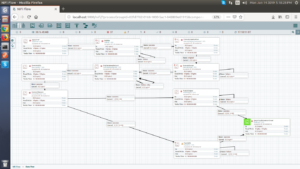
Solution:
- GetHTTP: Fetches data from an HTTP or HTTPS URL and writes the data to the content of a FlowFile.Drag and drop the GetHTTP processor and configure is as follows:
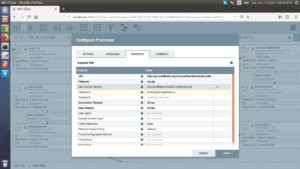
Fig: GetHTTP Configuration
Properties:
URL: Paste the URL from where you want to extract data. In our case, we have used http://api.worldbank.org/v2/countries/all/indicators/NE.EXP.GNFS.ZS?downloadformat=csv
Filename: The filename to assign to the file when pulled.
SSL Context Service: Access the file over HTTP you have to generate SSL Context Service. In this case, we have created a StandardRestrictedSSLContextService and the configuration is as follows:
StandardRestrictedSSLContextService:
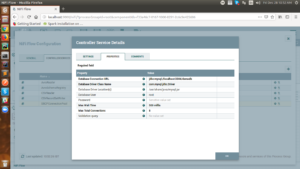
Fig: StandardRestrictedSSLContextService Configuration
Properties:
Keystore Filename: The fully-qualified filename of the Keystore
- PutFile:It writes the contents of a FlowFile to the local file system. Drag and drop the PutFile Processor and configure it as follows:
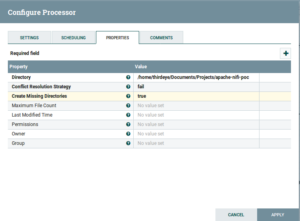
Fig: PutFile Configuration
Properties:
Directory: The directory to which files should be written.
- ExecuteStreamCommand:Drag and drop the ExecuteStreamCommand Processor and configure is as follows:
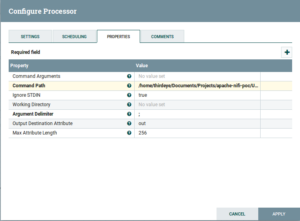
Fig: ExecuteStreamCommand Configuration
- ExecuteScript: Drag and drop the ExecuteScript Processor and configure is as follows:
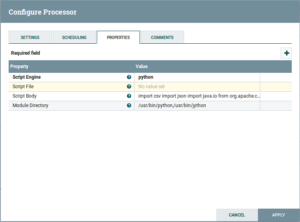
Fig: ExecuteScript Configuration
- PutDatabaseRecord: Drag and drop the PutDatabaseRecord Processor and configure is as follows:
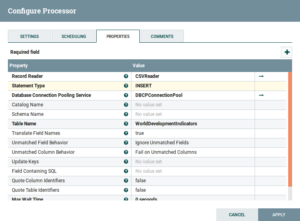
Fig: PutDatabaseRecord Configuration
DBCPConnectionPool:
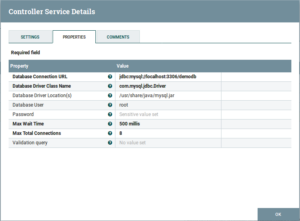
Fig: DBCPConnectionPool Configuration
CSVReader:
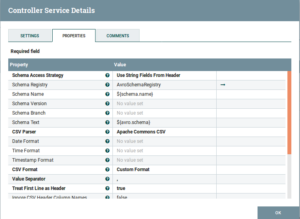
Fig: CSVReader Configuration
AvroSchemaRegistry:
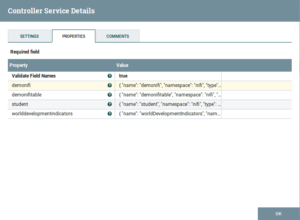
Fig: AvroSchemaRegistry Configuration
- ExecuteSQL: Drag and drop the ExecuteSQL Processor and configure is as follows:
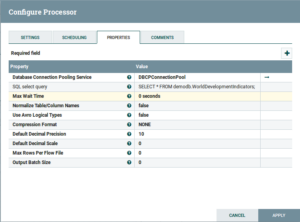
Fig: ExecuteSQL Configuration
- ConvertRecord: Drag and drop the ConvertRecord Processor and configure is as follows:
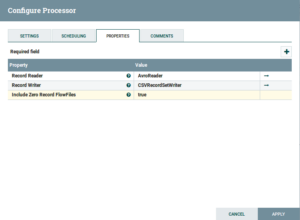
Fig: ConvertRecord Configuration
AvroReader:
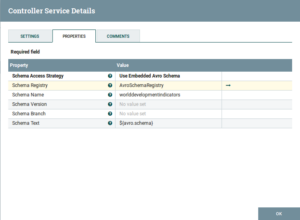
Fig: AvroReader Configuration
CSVRecordSetWriter:
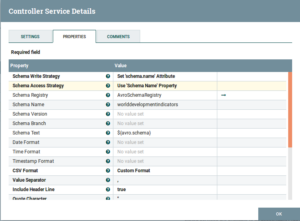
Fig: CSVRecordSetWriter Configuration
- PutS3Object: Drag and drop the PutS3Object Processor and configure is as follows:
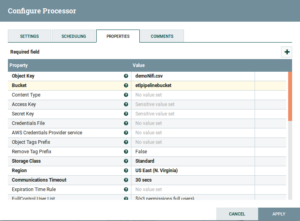
Fig: PutS3Object Configuration
- PutHDFS: Drag and drop the PutHDFS Processor and configure is as follows:
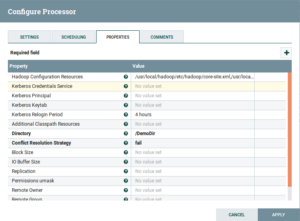
Fig: PutHDFS Configuration
- PutEmail: Drag and drop the PutEmail Processor and configure is as follows:
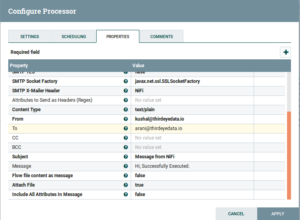
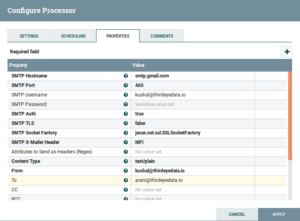
Fig: PutEmail Configuration
In this process, we have done the Data EXTRACTIONby API calls. Then we performed various TRANSFORMATION operations to derive meaningful data from it. After that, we LOADED the data in a SQL table to complete the steps of ETL Pipeline. And finally, SCHEDULEDthe operation using Apache NiFi.










