Neuro-Symbolic Planning with LLMs in 2025
LLM agents can talkthrough tasks, but they still falter on long-horizon plans with tight preconditions and side effects. Independent studies continue to show that when LLMs plan autonomously, without formal verification or a search-based planner – the best models execute valid plans only a small fraction of the time (e.g., ~12% success across IPC-style domains in controlled evaluations of GPT-4), underscoring why “prompting harder” isn’t enough for production reliability.
By contrast, classical symbolic planners (e.g., Fast Downward) produce provably validplans once a domain is specified in a formal language like PDDL. The last 24 months have therefore converged on a hybrid answer: neuro-symbolic planning, where LLMs modelthe world (translate natural language and logs into formal artifacts) while symbolic plannersguaranteethe plan.
Canonical exemplars include LLM+P(LLM to/from PDDL + classical planner) and newer frameworks like LLMFP(formalized programming to cast tasks as optimization problems) and LOOP(an iterative LLM↔planner conversation with feedback and causal memory). Together they define a practical path to reliable, auditable planning in 2025.
Why 2025 enterprises need neuro-symbolic planning
- Accuracy gap is real.Benchmarks repeatedly find that naively “LLM-as-planner” agents produce partial, non-executable action sequences; one meta-analysis reports that, on average, only the first ~2.65 actions of LLM-generated plans are executable versus ~8.4 steps for symbolic baselines.
- Cost and governance pressures.Teams must provethat agents won’t violate constraints (safety policies, budget limits, operational SLAs). Symbolic planners give you explainability, traceability, and hard constraints by design.
- Adoption signals.2025 has seen neuro-symbolic approaches move from research to operations. Reporting indicates Amazon is applying neuro-symbolic techniques across teams – from its Rufus shopping assistant to the new Vulcan warehouse robots; precisely to reduce hallucinations and enforce task-level rigor.
The bottom line is if your agent must commit inventory, allocate fleet capacity, schedule maintenance, or orchestrate workflows with penalties for failure, you need a planner that can provepreconditions and effects, not just “sound plausible.”
What is a “planning problem” in this context?
A classical planning instance is defined by a domain(types, predicates, actions with preconditions/effects) and a problem(initial state, objects, goal conditions). Solutions are sequences (or graphs) of actions that transform the initial state to any goal state while respecting all preconditions. LLMs help authorthese artifacts from natural language and telemetry; planners like Fast Downward then searchfor a valid (often optimal) plan, and LLMs can verbalizethe plan back to human-readable steps.
State of the art in 2025: What Actually Works
1) LLM+P (LLM ↔ PDDL ↔ Planner)
Pattern:Humans author the domain PDDL (once). The LLM translates task descriptions and current world facts into problem PDDL; a symbolic planner computes the plan; the LLM renders it back to NL and code for execution.
Why it matters:It consistently outperforms direct LLM planning, because the planneris doing the hard work under formal constraints. The original LLM+P paper remains a solid blueprint for teams taking their first neuro-symbolic step.
2) Dynamic planning under uncertainty (belief-state sampling)
Pattern:Keep a set of beliefs Bfor unknowns, sample possible worlds, have the LLM generate problem PDDL for each sample, run a planner, pick a plan by a criterion (e.g., cost or robustness), execute, observe, and update (W,B)iteratively.
Why it matters:It’s a pragmatic way to operate in partial-knowledge environments (e.g., inventory location uncertainty, sensor dropouts) while still preserving the formality of symbolic planning. Recent surveys frame this as a core direction for “LLM as modeling interface, symbolic as validator.”
3) LLMFP (LLM-based Formalized Programming)
Pattern:Instead of PDDL, the LLM formalizes the task as an optimization programfrom scratch and solves it with off-the-shelf solvers, aiming at generality across planning and decision tasks.
Evidence:The 2024/2025 LLMFP work reports large gains versus strong baselines across diverse tasks (e.g., ~83–87% optimality rates for top LLMs on their suite), showing that formalization firstcan be a robust alternative to direct planning prompts.
4) LOOP (iterative LLM↔planner loop with causal memory)
Pattern:Treat planning as a conversationbetween neural and symbolic components: the LLM drafts/repairs PDDL, the planner validates/rejects with concrete counterexamples, and a causal memory learns from execution traces. Early results show large gains over both LLM-only and one-shot neuro-symbolic baselines on IPC-style domains.
5) The empirical guardrails
Multiple 2025 studies reiterate that pure LLM planning remains brittle; without a planner or verifier, success rates remain low (often ≤20–30% depending on domain and setup). This is why every production-ready pattern uses a validator(planner, program verifier, or solver) in the loop.
A Reference Architecture for B2B systems
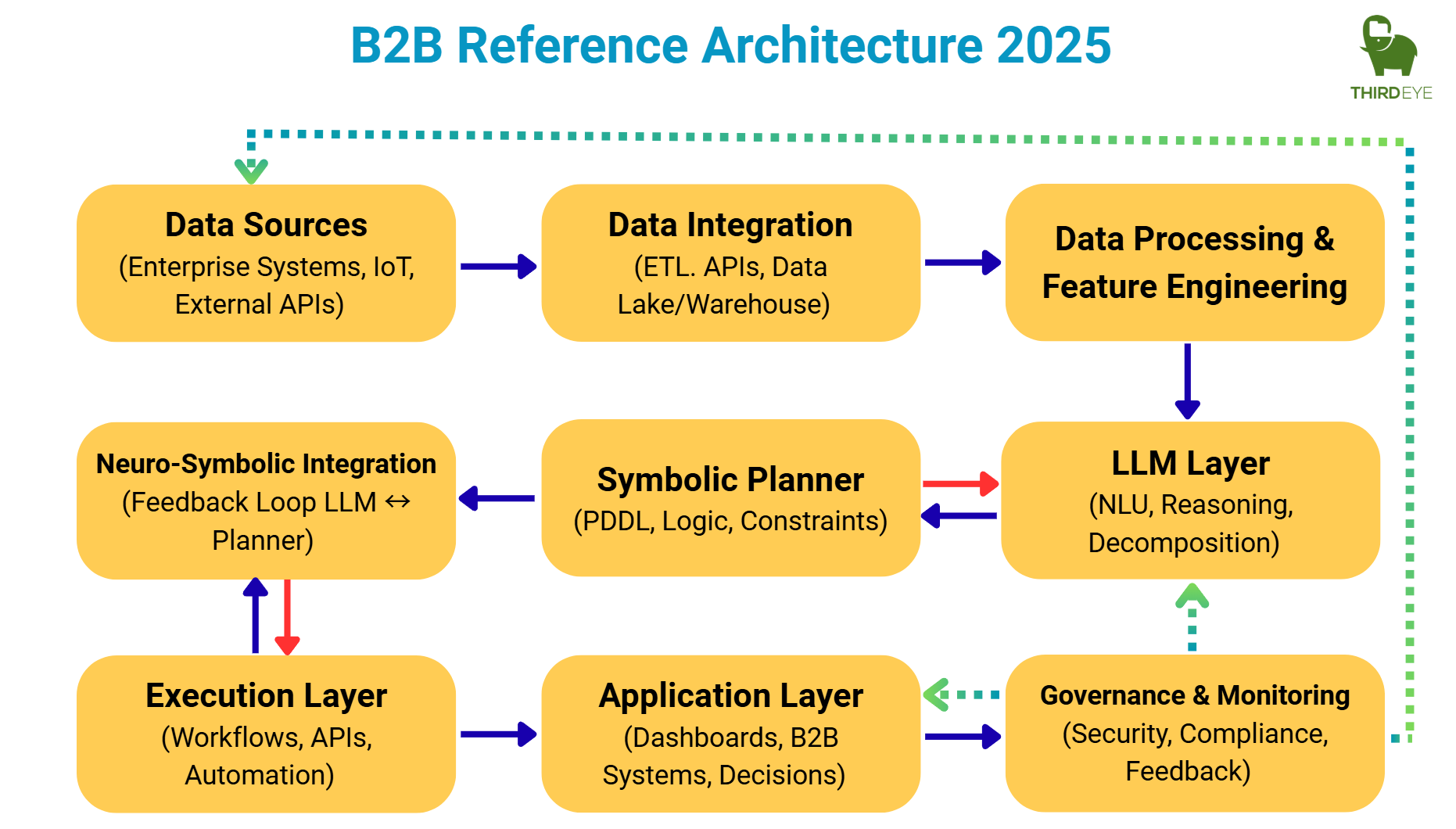
Below is a production-oriented architecture we recommend for enterprises adopting neuro-symbolic planning. It aligns with the literature but adds operational rigor.
- Ingestion & grounding
– Sources:tickets, runbooks, IoT/sensor feeds, ERP/WMS/CRM events, knowledge bases.
– LLM tasks:schema mapping, entity/affordance extraction, constraint mining (“never ship hazmat by air”), and conflict detection.
– Artifacts:Domain PDDL(versioned), Problem PDDL(ephemeral per request), or formal optimization programs(LLMFP style). - Plan synthesis
– Symbolic planner(e.g., Fast Downward, LAMA configs) or solver backends(MILP/CP-SAT).
– Properties:soundness (preconditions/effects honored), optimality (cost metric), or bounded-suboptimal guarantees. - Neuro-symbolic loop
– Verification:planner returns plan or minimal counterexample; LLM revises domain/problem; optionally belief samplingfor uncertainty.
– Learning:store traces (s, a, s′) and failure cases; causal memoryidentifies mis-specified effects and schema drift. (LOOP-style). - Policy & guardrails
– Hard constraints:regulatory, safety, budget, SoD (segregation of duties) encoded as predicates and goal constraints.
– Audit:persist domain/problem/plan triples, solver logs, and LLM deltas for post-hoc review. (This is where neuro-symbolic shines in compliance.) - Actuation
– Connectors:workflow engines, RPA, microservices, robot controllers (ROS2), or orchestration layers.
– Human-in-the-Loop:gated approval for irreversible actions; LLM generates natural-language rationales from the formal plan. - Monitoring & evaluation
– KPIs:plan validity rate, correction rate, average plan cost vs. target, constraint-violation rate (should be zero), and cycle times.
– Benchmarks:maintain a local suite derived from ICP/IPC-style domains and your live data to prevent regressions.
Implementation patterns that avoid common pitfalls
Pattern A: “Translator in the loop” (most robust starting point)
- You provide:a stabledomain PDDL vetted by SMEs.
- LLM provides:problem instantiation from live data + explanation layers.
- Planner provides:optimal or satisficing plans.
- Why:You lock the semantics; the LLM cannot “invent” effects that aren’t in the domain. This alone eliminates most cascade errors. (LLM+P pattern.)
Pattern B: “Formalize as optimization” (when PDDL is not a fit)
- Use when:tasks have natural costs and constraints (e.g., workforce scheduling, ad pacing, fleet routing), and you want solver-grade guarantees without maintaining PDDL ontologies.
- Stack:LLM → formal program (MILP, Max-SAT) → solver. (LLMFP pattern.)
Pattern C: “Iterative repair with causal memory” (for change-heavy domains)
- Use when:the world changes faster than domain models can be manually curated (e.g., new SKUs and shelf geometry in fulfillment).
- Stack:LLM drafts/refines domain+problem; planner returns counterexamples; causal module updates effects based on execution traces. (LOOP pattern.)
Hard-won lessons from 2025 evaluations
- Assume the LLM will over-generalize.Studies show that naively generated plans look plausible but break quickly; on average, only a couple of first actions are executable. Always verify with a planner or a solver.
- Feedback is gold.The biggest gains come from using planner feedbackto drive LLM repairs (missing preconditions, wrong effects), not from larger prompts alone. This is the core idea behind LOOP.
- Uncertainty must be explicit.Treat unknowns as beliefs, sample worlds, and select robust plans; do not let the LLM silently “assume away” unknowns.
- Benchmarks translate to ops, if you keep them live.Take canonical domains (BlocksWorld, Logistics, Depot) and instantiate them with your objects, costs, and constraints. Use them as CI for your agent.
- It’s not just accuracy; it’s cost.Tree-of-Thought-style exploration can balloon token usage by 50–100× with limited reliability gains. Iterative LLM↔planner loops typically achieve better reliability at lower cost.
What “good” looks like: KPIs and Governance
- Plan validity rate (PVR):% of plans that pass symbolic validation. Target ≥ 95% before enabling auto-execution in production. (LLM+Planner should get you there.)
- Constraint-violation rate:should be zeroin validated plans; any non-zero event indicates a modeling gap in the domain/problem generator.
- Repair loop count:average number of LLM↔planner iterations to reach a valid plan. Healthy systems converge in ≤3 loops for routine tasks.
- Optimality delta:solver cost vs. business target (e.g., travel time, SLA penalty). Track by scenario type (rush orders vs. routine).
- Human-approval rate:aim to reduce over time only afteryour PVR and constraint metrics stabilize.
Governance tips:
- Version everything.Treat domain PDDL and formal programs like code. CI should run benchmark suites on each change.
- Defense in depth.Keep hardconstraints in both the formal layer and at execution (policy checks), not just in prompts.
- Evidence trails.For audits, persist the NL request, the generated formal spec, solver logs, the returned plan, and the execution outcome.
Example adoption roadmap (90 days)
Weeks 1–3: Model your domain
- Inventory objects, actions, and invariants with SMEs.
- Author Domain PDDL(or define an optimization schema). Validate with a tiny “golden” set of tasks.
Weeks 4–6: Close the loop
- Implement LLM→Problem PDDL generation from live data.
- Run Fast Downward(seq-opt-fdss-1 or LAMA) or a solver backend; enforce plan validation before any actuation.
Weeks 7–9: Add robustness
- Introduce belief-state samplingfor unknowns; add the iterative repairloop using planner counterexamples.
- Start capturing traces for causal memoryand automatic model repairs (LOOP-style).
Weeks 10–12: Productionize
- Add human-approval gates, monitoring, and CI benchmarks.
- Begin limited auto-execution on low-risk workloads; expand coverage as PVR and violation metrics stabilize.
How ThirdEye Data approaches neuro-symbolic planning
Architectural stance.We advocate “LLM as modeler; planner/solver as guarantor.” We start with a minimal, testable domain model and use the LLM for translation, enrichment, and repair, not free-form decision-making.
Engineering patterns we deploy:
- Schema-first grounding:deterministic extractors where possible, LLMs where necessary, with validation layers.
- Dual formalizations:PDDL + optimization templates in parallel for the same task family, selected by meta-policy at runtime (cost vs. optimality vs. latency).
- Repair-by-counterexample:automated loops where infeasible plans trigger targeted edits (missing preconditions, wrong effects) and regenerate only the impacted sections – mirroring LOOP principles.
- Live benchmarks:customer-specific IPC-style suites run on every change to domains, prompts, or planner configs.
What clients gain:
- Reliability:measurable jumps in plan validity vs. LLM-only baselines, often from <30% to >90% beforea human sees the plan.
- Auditability:every decision has a formal lineage (spec → plan → execution), easing compliance reviews.
- Cost control:fewer agent retries, bounded search via classical planners/solvers, and eliminations of “think-until-budget-explodes” loops.
ThirdEye Data helps enterprises implement the above stack end-to-end: domain modeling, neuro-symbolic architecture, verification loops, and integration to real systems. If you want this rigor behind your agents in 2025, we can start with a discovery sprint and deliver a validated pilot in weeks. Talk to usto discuss your use case.
Frequently asked build-time questions
Do we have to write PDDL by hand?
Not for everything. Keep the domainhand-reviewed (once per domain), then let the LLM instantiate problemsfrom NL tasks and live data. LLMs are increasingly good at PDDL syntax; they still need validation for semantics.
What if our world changes daily (new SKUs, shelves, rules)?
Adopt an iterative repairloop with planner feedback and causal memory; this pattern is designed specifically for drifting environments.
Why not just use “reasoning-tuned” LLMs?
They help, but recent studies in 2025 show that even with specialized prompting and post-hoc plan “linting,” pipelines rarely match the reliability of classical planning; average autonomous success typically remains far below production thresholds without a formal validator.
Is this real in the wild, or just papers?
It’s shipping. Public reporting highlights neuro-symbolic methods behind large-scale assistants and robotics (e.g., Amazon Rufus and Vulcan) to improve reliability and reduce hallucinations, because formal reasoning is cheaper than mistakes.
Closing perspective for 2025
The field’s consensus is no longer “can LLMs plan?” – it is “how should LLMs collaborate with planners and solvers?”The winning pattern in 2025 is neuro-symbolic: LLMs for language, schema induction, and rapid model repair; symbolic enginesfor correctness, search, and guarantees. If you encode constraints where they musthold (formal layer), and let language models do what they do best (translation and synthesis), you get reliable, explainable agents that your operations teams will actually trust.
If you’re building or upgrading an agentic roadmap this year, start small with LLM+P, add belief-state sampling for uncertainty, and graduate to iterative repair with causal memory. Measure progress with plan validity, constraint-violation rate, and repair-loop counts, not just win-rate on demos. That’s how you move from “cool demo” to durable business value.
References & further reading
- LLM+P (LLM with classical planner)— original paper and details. arXiv+1
- LLMFP (formalized programming)— paper and ICLR 2025 entry. arXivOpenReview
- LOOP (neuro-symbolic iterative loop)— arXiv preprint (2025). arXiv
- Surveys (2025)— “LLMs as Planning Formalizers/Modelers” and “A Survey of Task Planning with LLMs.” ACL AnthologyScience Advances
- Empirical limits of pure LLM planning— NeurIPS 2023 study (~12% autonomous success), 2025 analyses on executability and success rates. NeurIPS ProceedingsarXiv
- Industry signals— neurosymbolic AI at Amazon (Rufus, Vulcan). Wall Street JournalThe Guardian