NLTK: Unlocking the Power of Natural Language in Python
Imagine trying to read hundreds of documents, tweets, or customer reviews and extract meaningful insights manually. Sounds impossible, right? This is where NLTK (Natural Language Toolkit)comes into play — a Python library that brings the power of Natural Language Processing (NLP)to your fingertips.
NLTK allows developers, data scientists, and researchers to analyze, process, and understand human language at scale. From tokenizing text to performing sentiment analysis, NLTK bridges the gap between raw textual data and actionable intelligence.
In this article, we’ll dive deep into NLTK: what it is, how it works, its applications, pros and cons, alternatives, industry insights, and real-world projects.
NLTK Overview
What is NLTK?
NLTK (Natural Language Toolkit)is an open-source Python librarydesigned for text processing and computational linguistics. It provides easy-to-use interfaces to over 50 corporaand lexical resources, including WordNet, along with text processing librariesfor classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
Essentially, NLTK is like a Swiss Army knife for text— allowing you to break down sentences, analyze structure, and extract meaning from raw data.
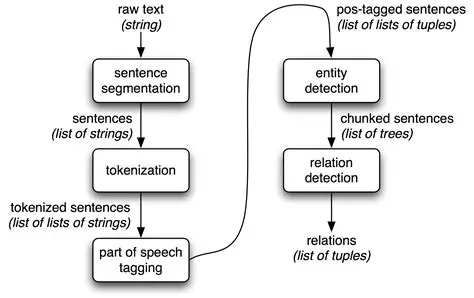
Image Courtesy: devopedia
History and Evolution
NLTK was developed in 2001 by Steven Bird and Edward Loperat the University of Pennsylvania. Its primary goal was to provide tools for teaching, research, and experimentation in NLP. Over two decades, it has become a trusted libraryfor both educational purposes and industry-level text analysis.
Why NLTK Matters
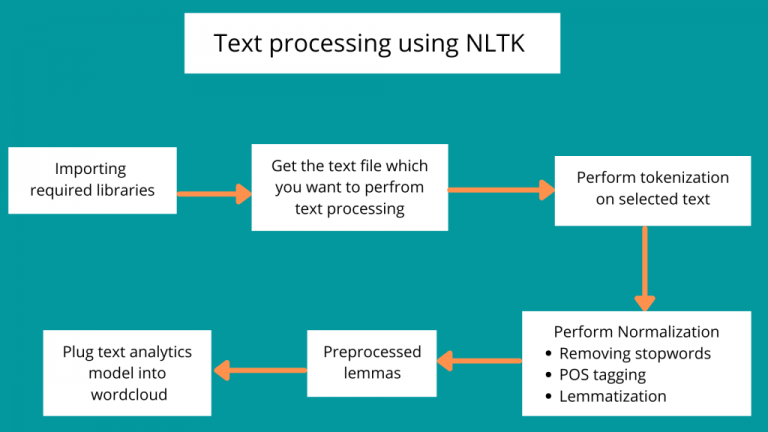
Image Courtesy: devopsschool
- Educational Value:Perfect for beginners learning NLP concepts
- Rich Resources:Comes with extensive datasets, corpora, and lexical resources
- Python Integration:Works seamlessly with Python’s data ecosystem, including Pandas and Scikit-learn
- Flexibility:Supports tokenization, POS tagging, named entity recognition, parsing, and sentiment analysis
NLTK empowers users to understand text data programmatically, opening doors to applications in chatbots, sentiment analysis, text summarization, and AI-driven customer insights.

Image Courtesy: slideshare
How NLTK Works
NLTK simplifies NLP by breaking text processing into modular, reusable components. Let’s explore its core functionalities:
- Tokenization
Tokenization is the process of splitting text into meaningful units — words, sentences, or phrases.
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
text = “NLTK is amazing! It simplifies text processing.”
words = word_tokenize(text)
sentences = sent_tokenize(text)
print(words)
print(sentences)
- Word Tokenization:Breaks sentences into individual words
- Sentence Tokenization:Breaks paragraphs into sentences
- Why it matters:Tokenization is often the first step in NLP pipelines
- Stemming and Lemmatization
- Stemming:Reduces words to their root form (e.g., “running” → “run”)
- Lemmatization:Converts words to their dictionary form, considering context (e.g., “better” → “good”)
from nltk.stem import PorterStemmer, WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem(“running”))
print(lemmatizer.lemmatize(“better”, pos=’a’))
These processes are essential for text normalization, improving model accuracy.
- Part-of-Speech (POS) Tagging
POS tagging labels words with their syntactic role, such as nouns, verbs, adjectives, etc.
from nltk import pos_tag
tokens = word_tokenize(“NLTK simplifies text processing.”)
tags = pos_tag(tokens)
print(tags)
- Applications:Named entity recognition, parsing, and understanding sentence structure
- Named Entity Recognition (NER)
NER identifies entitieslike people, locations, organizations, dates, and more.
from nltk import ne_chunk
text = “Apple is looking at buying a UK startup.”
tokens = word_tokenize(text)
tags = pos_tag(tokens)
entities = ne_chunk(tags)
print(entities)
- Crucial for information extraction, question answering, and chatbots
- Corpus and Lexical Resources
NLTK comes with built-in datasetsand lexical tools:
- Corpora:Gutenberg, Brown, Reuters, Webtext
- Lexical databases:WordNet (synonyms, antonyms, hypernyms)
- Frequency analysis:Understand word usage and patterns in large text datasets
- Text Classification
NLTK provides tools for supervised learningon text data:
- Naive Bayes Classifier:Common for spam detection or sentiment analysis
- Feature Extraction:Bag-of-words, TF-IDF
- Training Pipelines:Create models directly within Python for text classification tasks

Image Courtesy: haleshot
Use Cases / Problem Statements Solved with NLTK
NLTK’s capabilities allow it to address a variety of real-world NLP challenges:
- Sentiment Analysis
- Problem:Understand customer opinions from reviews or social media posts
- NLTK Solution:Tokenize, normalize, and classify text as positive, negative, or neutral
- Example:Amazon product review analysis or Twitter sentiment monitoring
- Chatbots and Conversational AI
- Problem:Design systems that understand and respond to human text
- NLTK Solution:Use tokenization, POS tagging, and pattern matching to interpret queries
- Example:Rule-based chatbots and initial NLP pipelines for conversational AI
- Text Summarization
- Problem:Extract key insights from large documents
- NLTK Solution:Tokenize, identify important sentences, and summarize content
- Example:Summarizing news articles or research papers
- Information Extraction
- Problem:Extract names, dates, and organizations from unstructured text
- NLTK Solution:Use POS tagging and NER to identify and extract entities
- Example:Extracting company names from financial reports
- Language Analysis and Research
- Problem:Linguists and researchers require tools for corpus analysis
- NLTK Solution:Analyze frequency distributions, concordances, and collocations
- Example:Studying word usage patterns in historical texts
- Preprocessing for Machine Learning
- Problem:Raw text is unsuitable for ML models
- NLTK Solution:Tokenize, stem/lemmatize, remove stopwords, and vectorize text for training
- Example:Preprocessing for NLP models like sentiment analysis, topic modeling, or classification
Pros of NLTK
- Comprehensive NLP Library:Covers almost all NLP tasks
- Educational Friendly:Perfect for learning and experimentation
- Rich Resources:Includes corpora, lexical databases, and pretrained datasets
- Python Ecosystem Integration:Works with Scikit-learn, Pandas, NumPy
- Open Source:Free, widely used, and actively maintained
- Extensible:Can integrate with deep learning frameworks like TensorFlow or PyTorch
Limitationsof NLTK
- Performance:Can be slower than spaCy for large-scale NLP tasks
- Complexity:Some functionalities require a strong understanding of NLP
- Limited Pretrained Models:Focuses on educational datasets rather than state-of-the-art embeddings
- Verbose Syntax:Can require multiple steps to achieve simple NLP tasks
Alternatives to NLTK
- spaCy:Faster, optimized for production NLP
- TextBlob:Simplified sentiment analysis and text processing
- Stanford NLP / Stanza:Advanced NLP with pretrained models
- Transformers (Hugging Face):Deep learning models for cutting-edge NLP tasks
- Gensim:Topic modeling and vector representations
Upcoming Updates / Industry Insightsof NLTK
- Integration with Deep Learning:Combining NLTK preprocessing with Hugging Face Transformers for state-of-the-art NLP
- Python Ecosystem Growth:Works well with Pandas, Scikit-learn, TensorFlow, and PyTorch
- Industry Adoption:Used in chatbots, text mining, sentiment analysis, recommendation systems, and AI research
- Cloud NLP Pipelines:Increasingly used in combination with cloud services for scalable text analytics
Project References regarding NLTK
Frequently Asked Questions of NLTK
Q1. What is the difference between NLTK and spaCy?
- NLTK is more comprehensive for learning and research; spaCy is optimized for production use with faster performance.
Q2. Can NLTK handle non-English languages?
- Yes, NLTK supports multiple languages but may require additional corpora and resources.
Q3. Is NLTK suitable for beginners?
- Absolutely. Its educational focus and extensive documentation make it beginner-friendly.
Q4. Does NLTK support deep learning?
- NLTK can preprocess text for deep learning pipelines but does not provide deep learning models itself.
Q5. Can NLTK be used in production?
- Yes, for small to medium-scale projects, though libraries like spaCy are preferred for high-performance needs.
Third Eye Data’s Take on NLTK
At Third EyeData, NLTKis likely consideredpart of older or foundational NLP toolkits, but not a primary framework in our published modern stack. While NLTK may still serve in text preprocessing, tokenization, or prototyping, for production NLP work we lean toward more scalable, performant, and modern libraries (spaCy, transformers) that better support deep learning and large-scale pipelines.
NLTK is a powerful gateway into the world of NLP, combining educational resources, Python integration, and versatile tools for processing human language. Whether you are building chatbots, analyzing sentiment, summarizing text, or researching linguistic patterns, NLTK provides the foundation for transforming raw text into actionable insights.
Call to Action
Ready to explore NLTK?
- Install NLTK: pip install nltk
- Download corpora:
import nltk
nltk.download(‘all’)
- Start tokenizing, tagging, and analyzing text in Python
- Combine NLTK with Scikit-learn, Pandas, or Transformersfor advanced NLP projects
Dive into NLTK today and turn words into intelligence!






