
by Monte Zweben
2019 has been a rocky year for the big three Hadoop distributors. From the internal optimism and external skepticism regarding the Cloudera/Hortonworks merger completing in January to MapR’s letter of impending doom in May and subsequent purchase by HPE, to Cloudera’s very bad Wednesday in June which saw a stock price collapse and the departure of Tom Reilly, the news has not been good. Perhaps the most telling piece of content comes from Cloudera’s quarterly earnings announcement that frames Hadoop’s challenge as one that needs a cloud solution:
“While some customers in the first quarter elected to postpone renewal and expansion of their agreements in anticipation of the new platform’s release, affecting our full year outlook, this customer feedback and enthusiasm validates demand for enterprise data cloud solutions in our target market.”
Complexity Kills

So many articles state that the public clouds have killed Hadoop, but as I have written here before, I have a somewhat contrarian view of the future of this distributed technology.
There are two major challenges to Hadoop:
- Operational Complexity — The DevOps burden of keeping a massively distributed system based on commodity hardware alive, performant, and secure.
- Developmental Complexity — The development burden of duct-taping many disparate compute and storage components together to form a functional solution without suffering from latency due to data movement.
The public cloud nailed operational complexity challenges. This was a major blow to the Hadoop distribution companies like Cloudera, Hortonworks, and MapR that were late to the cloud. AWS, Azure, and GCP nearly eliminate the operational complexity of operating the core components of the Hadoop ecosystem.
However, I believe there is still a substantial challenge to the successful adoption of this technology, even in the public cloud. There are literally hundreds of compute and storage solutions on AWS’s product page. Our view is that the industry is leaving too much to the developer.
Do You Want to Make the Car or Drive the Car?

Hadoop is a great set of technology components! We use it to build our data platform. But through my many conversations with CIO’s struggling with their Hadoop implementations, I have come to believe that the components may just be too low level. Metaphorically speaking, when we need transportation, we buy a car based on our transportation needs. We don’t buy separate car parts like fuel injectors, axles, engines, and suspension systems. We let those be assembled by the manufacturer.
Similarly, when you have to connect AWS Dynamo to run an application, AWS Redshift to analyze data, AWS SageMaker to build ML models, AWS EMR to run Spark-based ETL, etc. you are assembling the “car”. This is the so-called duct-tape of the “Lambda Architecture”.
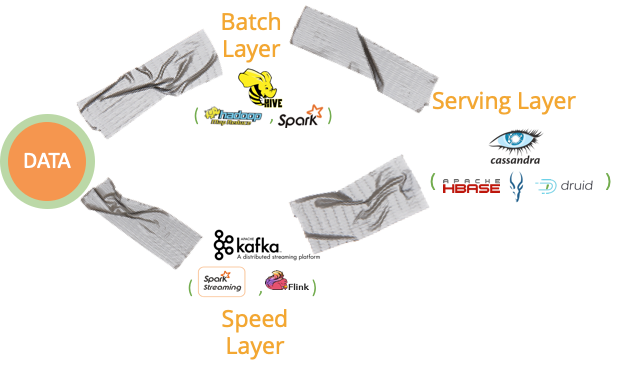
However, this leads to complexity and data movement. And data movement leads to latency often experienced as waiting for the data to be “ETL’d”. Additionally, the skills required to create these architectures are scarce and expensive.
So regardless of whether or not the operational complexity is removed by moving to the cloud — which is no small task indeed — you still suffer from the integration complexity of duct-taping all the compute and storage together.
A Pre-Integrated Packaged Approach

Our view is that, like the “car” for transportation, companies need massively scalable infrastructure for combined operational, analytical, and ML workloads, but they should not have to assemble this functional capability themselves. We believe there are certain components of Hadoop that are great to embed and integrate to enable companies to both build new applications and modernize their existing applications (and you can see how we did it at Splice Machine here). Others integrate the components together in other ways. But nonetheless, we believe that this pre-integration is essential and until this is widespread, Hadoop will still be hard — even in the public cloud.



