Azure HDInsight Spark
Overview
Introduction to Spark on HDInsight
This article provides you with an introduction to Spark on HDInsight. Apache Spark is an open-source parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. Spark cluster on HDInsight is compatible with Azure Storage (WASB) as well as Azure Data Lake Store. Hence, your existing data stored in Azure can easily be processed via a Spark cluster.
When you create a Spark cluster on HDInsight, you create Azure compute resources with Spark installed and configured. It only takes about 10 minutes to create a Spark cluster in HDInsight. The data to be processed is stored in Azure Storage or Azure Data Lake Store. See Use Azure Storage with HDInsight.
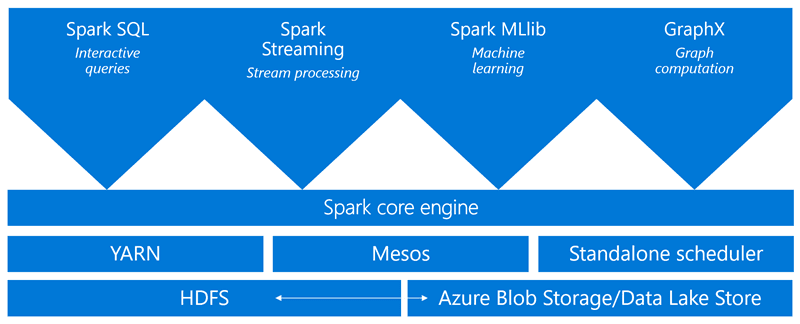
Spark vs. traditional MapReduce
What makes Spark fast? How is the architecture of Apache Spark different than traditional MapReduce, allowing it to offer better performance for data sharing?
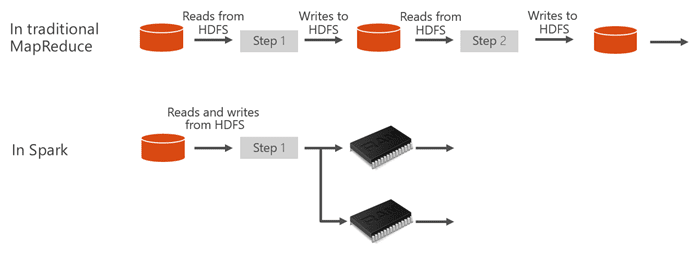
Spark provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly, much more quickly than disk-based systems. Spark also integrates into the Scala programming language to let you manipulate distributed data sets like local collections. There’s no need to structure everything as map and reduce operations.
In Spark, data sharing between operations is faster since data is in-memory. In contrast, Hadoop shares data through HDFS, which takes longer to process.
What is Apache Spark on Azure HDInsight?
Spark clusters on HDInsight offer a fully managed Spark service. Benefits of creating a Spark cluster on HDInsight are listed here.
| Feature | Description |
|---|---|
| Ease of creating Spark clusters | You can create a new Spark cluster on HDInsight in minutes using the Azure portal, Azure PowerShell, or the HDInsight .NET SDK. See Get started with Spark cluster in HDInsight |
| Ease of use | Spark cluster in HDInsight include Jupyter and Zeppelin notebooks. You can use these notebooks for interactive data processing and visualization. |
| REST APIs | Spark clusters in HDInsight include Livy, a REST API-based Spark job server to remotely submit and monitor jobs. |
| Support for Azure Data Lake Store | Spark cluster on HDInsight can be configured to use Azure Data Lake Store as an additional storage, as well as primary storage (only with HDInsight 3.5 clusters). For more information on Data Lake Store, see Overview of Azure Data Lake Store. |
| Integration with Azure services | Spark cluster on HDInsight comes with a connector to Azure Event Hubs. Customers can build streaming applications using the Event Hubs, in addition to Kafka, which is already available as part of Spark. |
| Support for R Server | You can set up a R Server on HDInsight Spark cluster to run distributed R computations with the speeds promised with a Spark cluster. For more information, see Get started using R Server on HDInsight. |
| Integration with third-party IDEs | HDInsight provides plugins for IDEs like IntelliJ IDEA and Eclipse that you can use to create and submit applications to an HDInsight Spark cluster. For more information, see Use Azure Toolkit for IntelliJ IDEA and Use Azure Toolkit for Eclipse. |
| Concurrent Queries | Spark clusters in HDInsight support concurrent queries. This enables multiple queries from one user or multiple queries from various users and applications to share the same cluster resources. |
| Caching on SSDs | You can choose to cache data either in memory or in SSDs attached to the cluster nodes. Caching in memory provides the best query performance but could be expensive; caching in SSDs provides a great option for improving query performance without the need to create a cluster of a size that is required to fit the entire dataset in memory. |
| Integration with BI Tools | Spark clusters on HDInsight provide connectors for BI tools such as Power BI and Tableau for data analytics. |
| Pre-loaded Anaconda libraries | Spark clusters on HDInsight come with Anaconda libraries pre-installed. Anaconda provides close to 200 libraries for machine learning, data analysis, visualization, etc. |
| Scalability | Although you can specify the number of nodes in your cluster during creation, you may want to grow or shrink the cluster to match workload. All HDInsight clusters allow you to change the number of nodes in the cluster. Also, Spark clusters can be dropped with no loss of data since all the data is stored in Azure Storage or Data Lake Store. |
| 24/7 Support | Spark clusters on HDInsight come with enterprise-level 24/7 support and an SLA of 99.9% up-time. |
Spark cluster architecture
Here is the Spark cluster architecture and how it works:
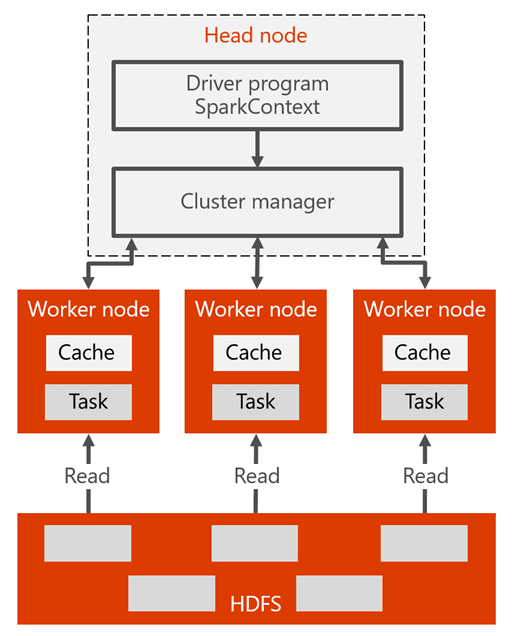
The head node has the Spark master that manages the number of applications, the apps are mapped to the Spark driver. Every app is managed by Spark master in various ways. Spark can be deployed on top of Mesos, YARN, or the Spark cluster manager, which allocates worker node resources to an application. In HDInsight, Spark runs using the YARN cluster manager. The resources in the cluster are managed by Spark master in HDInsight. That means the Spark master has knowledge of which resources, like memory, are occupied or available on the worker node.
The driver runs the user’s main function and executes the various parallel operations on the worker nodes. Then, the driver collects the results of the operations. The worker nodes read and write data from and to the Hadoop distributed file system (HDFS). The worker nodes also cache transformed data in-memory as Resilient Distributed Datasets (RDDs).
Once the app is created in the Spark master, the resources are allocated to the apps by Spark master, creating an execution called the Spark driver. The Spark driver also creates the SparkContext and also starts creating the RDDs. The metadata of the RDDs are stored on the Spark driver.
The Spark driver connects to the Spark master and is responsible for converting an application to a directed graph (DAG) of individual tasks that get executed within an executor process on the worker nodes. Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads.
What are the use cases for Spark on HDInsight?
Spark clusters in HDInsight enable the following key scenarios:
Interactive data analysis and BI
Apache Spark in HDInsight stores data in Azure Storage or Azure Data Lake Store. Business experts and key decision makers can analyze and build reports over that data and use Microsoft Power BI to build interactive reports from the analyzed data. Analysts can start from unstructured/semi structured data in cluster storage, define a schema for the data using notebooks, and then build data models using Microsoft Power BI. Spark clusters in HDInsight also support a number of third-party BI tools such as Tableau making it an ideal platform for data analysts, business experts, and key decision makers.
Spark Machine Learning
Look at a tutorial: Predict building temperatures using HVAC data
Look at a tutorial: Predict food inspection results
Apache Spark comes with MLlib, a machine learning library built on top of Spark that you can use from a Spark cluster in HDInsight. Spark cluster on HDInsight also includes Anaconda, a Python distribution with a variety of packages for machine learning. Couple this with a built-in support for Jupyter and Zeppelin notebooks, and you have a top-of-the-line environment for creating machine learning applications.
Spark streaming and real-time data analysis
Spark clusters in HDInsight offer a rich support for building real-time analytics solutions. While Spark already has connectors to ingest data from many sources like Kafka, Flume, Twitter, ZeroMQ, or TCP sockets, Spark in HDInsight adds first-class support for ingesting data from Azure Event Hubs. Event Hubs is the most widely used queuing service on Azure. Having an out-of-the-box support for Event Hubs makes Spark clusters in HDInsight an ideal platform for building real time analytics pipeline.
What components are included as part of a Spark cluster?
Spark clusters in HDInsight include the following components that are available on the clusters by default.
- Spark Core. Includes Spark Core, Spark SQL, Spark streaming APIs, GraphX, and MLlib.
- Anaconda
- Livy
- Jupyter notebook
- Zeppelin notebook
Spark clusters on HDInsight also provide an ODBC driver for connectivity to Spark clusters in HDInsight from BI tools such as Microsoft Power BI and Tableau.
Source: Introduction to Spark on Azure HDInsight | Microsoft Docs
Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.

