What is Teradata?
Teradata is an RDBMS (relational database management system) which includes features:
- It’s built on completely parallel architecture which means single task will be divided into smaller chunks and compute simultaneously hence faster execution.
- Teradata system is a shared-nothing architecture in which each node is independent and self-sufficient. Also, each logical processor (AMP) is responsible only for their own portion of the database.
- Supporting industry standard ANSI SQL to communicate with Teradata.
- Teradata database can be accessed by multiple concurrent users from different client applications via popular TCP/IP connection or IBM mainframe channel connection.
Why use Teradata?
There are numerous reasons why clients choose Teradata over other databases.
- Linear scalability helps to support more users/data/queries/query complexity without losing performance. When system configuration grows performance increases linearly.
- The system is built on open architecture, so whenever any faster chip and device are made available it can be incorporated into the already build architecture.
- Automatic distribution of data across multiple processors (AMP) evenly. Components divide the task into approximately equal pieces so all parts of the system are kept busy to accomplish the task faster.
- Supports 50+ petabytes of data.
- Provides a parallel-aware Optimizer that makes query tuning unnecessary and gets it run efficiently.
- Single operation view for a large Teradata multi-node system via SWS (Service Workstation). This is mainly managed by Teradata GSC.
- Single point of control for the DBA to manage the database using Teradata Viewpoint.
- Compatible with large numbers of BI tool to fetch data.
Teradata Architecture
The main components of Teradata Architecture are PE(Parsing Engine), BYNET, AMP(Access Module Processor), Virtual Disk. Following is the logical view of the architecture:
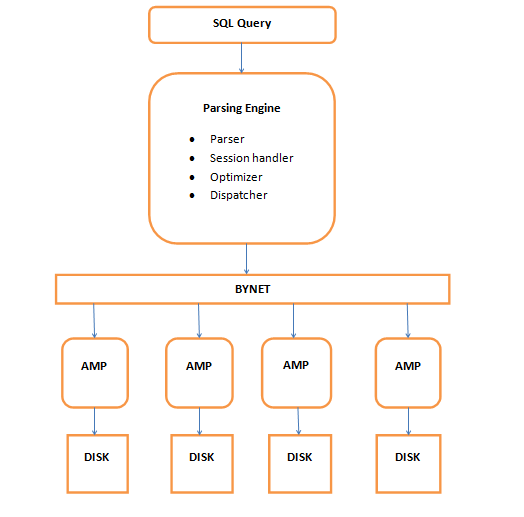
Parsing Engine
When a user fires an SQL query it first gets connected to the PE (Parsing Engine). The processes such as planning and distributing the data to AMPS are done here. It finds out the best optimal plan for query execution. The following are the processes performed by PE:
- Parser: The Parser checks for the syntax, if true forward the query to Session Handler.
- Session Handler: it does all the security checks, such as checking of logging credentials and whether the user has permission to execute the query or not.
- Optimizer: It finds out the best possible and optimized plan to execute the query.
- Dispatcher: The Dispatcher forwards the query to the AMPs.
BYNET
The BYNET acts as a channel between PE and AMPs. It acts as a communicator between the two. There are two BYNETs in Teradata ‘BYNET 0’ and ‘BYNET 1’. But we refer them as single BYNET system. The reason for having 2 BYNETs is:
- If one BYNET fails, the second one can take its place.
- When data is large, both BYNETs can be made functional which improves the communication between PE and AMPs, thus fastening the process.
AMP
Access Module Processor is a virtual processor which is connected to PE via BYNET. Each AMP has its own disk and is allowed to read and write in its OWN disk. This is called as ‘SHARED NOTHING ARCHITECTURE’. When the query is fired, Teradata distributes the rows of the table on all the AMPs and when it calls for any data all AMPs work simultaneously to give back the data. This is called PARALLELISM. The AMP executes any SQL requests in three steps
- Lock the table.
- Execute the operation requested.
- End the transaction.
Disk
Teradata offers a set of Virtual Disks for each AMP. The storage area of each AMP is called as Virtual Disk or Vdisk. The steps for executing the query are below:
- The user fires the query which is sent to PE.
- PE does the security and syntax checks and finds out the best optimal plan to execute the query.
- The table rows are distributed on the AMP and the data is retrieved from the disk.
- The AMP sends back the data through BYNET to PE.
- PE returns back the data to the user.
Life Cycle Of a Teradata Query
Teradata users or any other applications submit a query in the form of SQL (Structured Query Language) and receive the answer. But behind the scene, it has to pass many tests which determine its fate.
Below are the steps which describe the Life Cycle of a Teradata Query:
Query Submit:-
The starting point of a Teradata query starts when the user submits a query. A call level interface (CLI) prepares parcel from that SQL query. Parcels can be two types –
- Request parcel – contains SQL statement.
- Data parcel – contains any parameter values that may be supplied.
Connect to Database:-
Then parcels are sent to Micro Teradata Director Program (MTDP) which establish a session to the Teradata database. MTDP prepares a request message containing the parcel for transmission to the Teradata database via a network. A Micro Operating System Interface (MOSI) is used to accept this request message to the operating system and network protocol like TCP/IP.
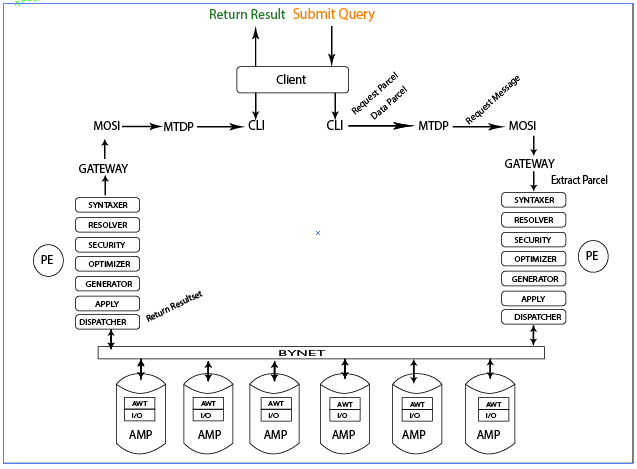
Extract Parcel:-
The PE receives the request message via gateway and PE will extract request parcel and data parcel. The PE is composed of several modules: syntax, resolver, security, optimizer, generator, and dispatcher.
Passes through security:-
- Syntaxer: Check the SQL query for proper syntax.
- Resolver: look up for the existence of objects in the data dictionary.
- Security: Determine if the user or database has proper access rights.
- Optimizer: It creates a most optimal plan for a query.
- Generation: Create steps for the winning plan.
- Dispatcher: Dispatches the steps to AMP via bynet.
Execute the query:-
Each AMP owns a portion of data and manages its own sets of lock and has its own sets of a data dictionary. Each one works independently of the other AMPs. Execution steps are received in parallel by all AMPs participating in the step, and an AMP worker task (AWT) on each AMP is assigned to execute the step.
AWT may sort, aggregate and redistribute the data as needed to produce answer set.
Produce resultSets:-
Each participating AMP will return its portion of a result to the Bynet which merge all the result set and prepare the final result and pass it to the dispatcher.
Return Answer to the user:-
Dispatcher now packages the result into response parcel and dispatch it to the Gateway to deliver over the network connection as a response message. The response parcel is then extracted from response message and the answer set is returned to the user.
Source: Introduction to Teradata
Transforming Enterprises with
Data & AI Services & Solutions.
ThirdEye delivers Data and AI services & solutions for enterprises worldwide by
leveraging state-of-the-art Data & AI technologies.







{kind=link}